You use ai data pipelines to turn raw data into insights that drive ai and machine learning. These pipelines help you collect, clean, and prepare information so your ml models can learn and make predictions. Many organizations see a strong return on investment, with some reaching up to 10.3 times ROI by optimizing their pipelines. You also notice faster results, often within two years, as better forecasting leads to smarter resource use and steady growth. As more companies explore automation and generative ai, you stay ahead by understanding how these systems work.
You use an ai data pipeline to move information from its source to a place where you can analyze it. This process helps you prepare data for ai and machine learning tasks. You start by collecting raw data from sources like sales systems, inventory databases, or supplier records. You clean and transform this data, removing errors and filling in missing values. You select features that help your model learn better. You split the data into training, validation, and test sets. You choose the right model and train it using the training data. You evaluate how well the model works and adjust its settings to improve results. You test the final model and deploy it so it can make predictions in real time. You monitor the model to make sure it stays accurate and reliable.
Here is a typical sequence in an ai data pipeline:
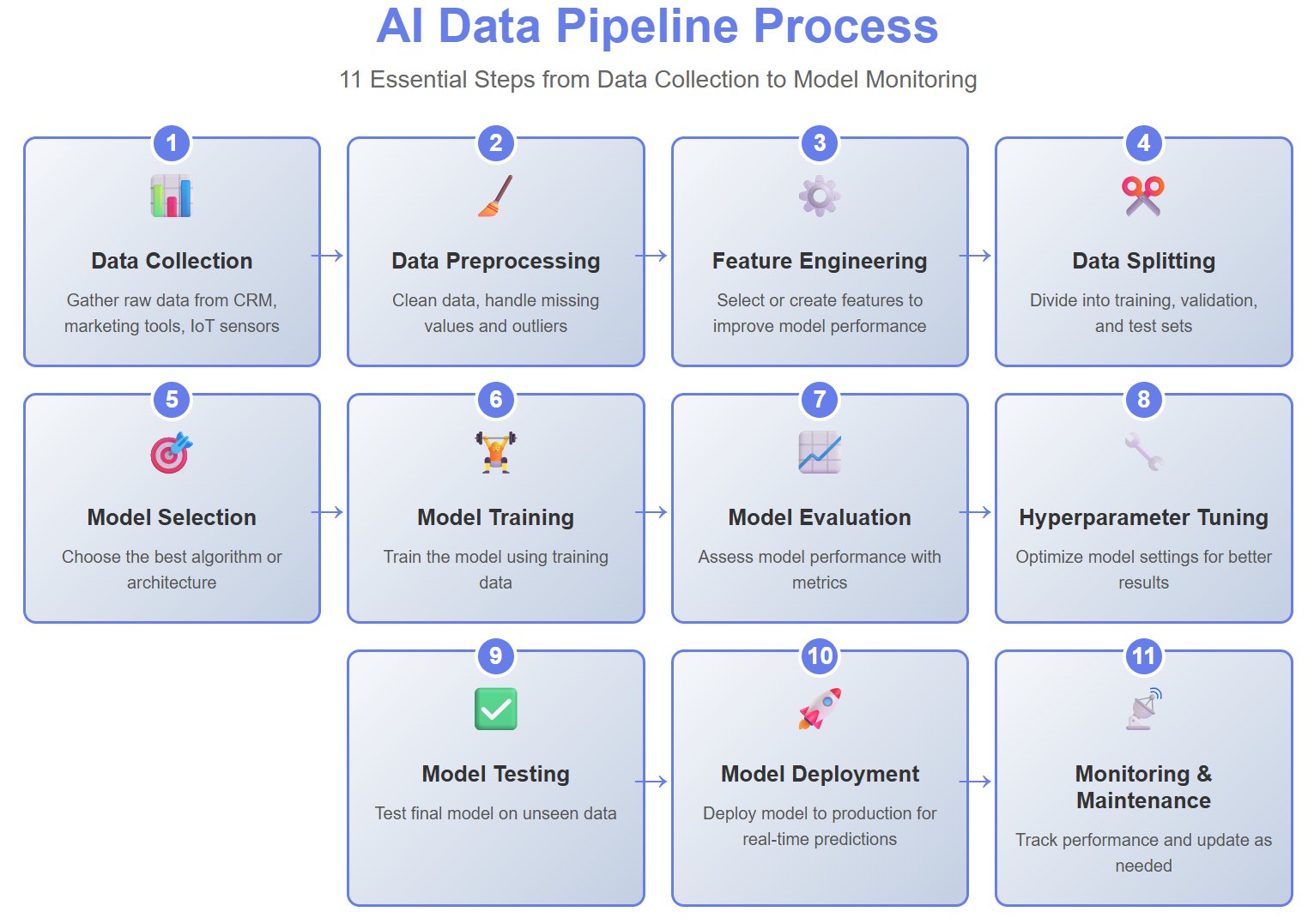
You build an ai data pipeline using several main components.
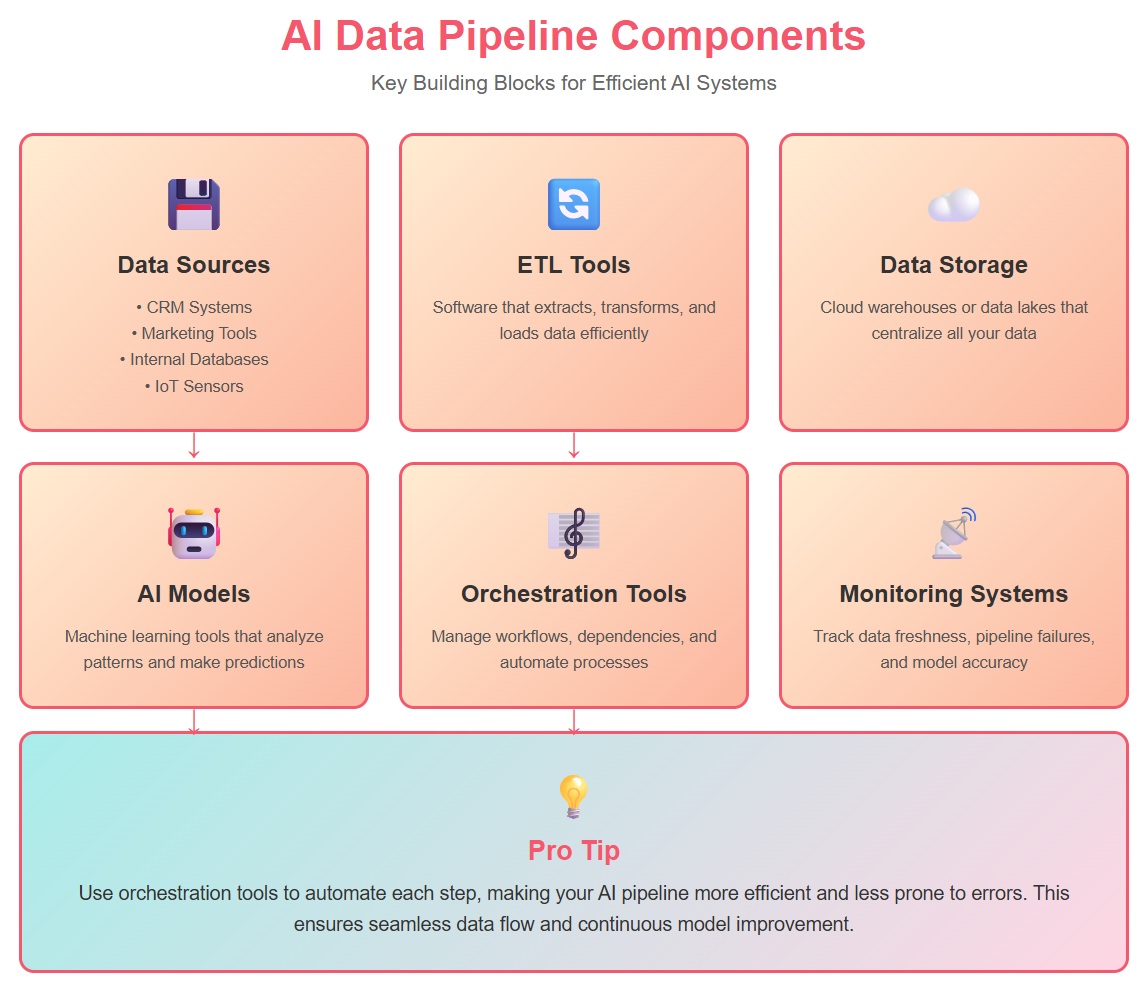
Tip: You can use orchestration tools to automate each step, making your ai pipeline more efficient and less prone to errors.
You rely on ai data pipelines to make sense of large amounts of information. These pipelines help you automate tasks that used to take hours or days. You can clean, transform, and analyze data quickly. You uncover patterns and generate insights faster than with traditional methods. You save money because you need less manual work. You reduce errors and improve the accuracy of your results. You make decisions in real time, which helps your business stay competitive.
Many organizations choose ai data pipelines because they offer speed, scalability, and cost-efficiency. You can process huge datasets without slowing down. You spend less on labor and operational costs over time. You also avoid problems that come from poor data quality. Bad data can delay projects, increase costs, and undermine trust in your ai systems. You need to follow rules about fairness, accountability, and transparency. If you do not, you risk fines and damage to your reputation.
Here is a table that shows the benefits and challenges of using ai data pipelines:
| Benefit | Challenge Without AI Data Pipeline |
|---|---|
| Automates tedious tasks | Poor data undermines trust |
| Reduces errors | Delays project timelines |
| Enables real-time decisions | Inflates operational costs |
| Saves money | Compliance issues and fines |
| Improves accuracy | Difficulty explaining decisions |
You see that ai pipelines help you avoid many common problems. You gain more control over your data and make better decisions for your business.

You start the ai data pipeline lifecycle with data ingestion and integration. This stage brings together information from many sources, such as APIs, databases, and data lakes. You can use batch or streaming modes, depending on your needs. Batch mode works well for scheduled updates, while streaming mode handles real-time data for instant analysis.
Here is a table that shows the typical steps in this stage:
| Step | Description |
|---|---|
| Data Collection | You gather data from sources like APIs, data lakes, and databases. |
| Data Cleaning | You sort and clean raw data to remove inaccuracies and inconsistencies. |
| Data Transformation | You normalize and transform data into a format suitable for ai applications, including feature engineering. |
| Data Integration | You integrate processed data into machine learning models for analysis and predictions. |
You often use specialized tools to help with data integration. Some popular options include Fivetran, Apache Kafka, Talend, AWS Glue, and Google Cloud Dataflow. These tools automate extraction, loading, and transformation, making your big data pipeline more efficient and scalable.
Tip: You can improve your data pipeline by choosing tools that match your business needs and technical skills.
After ingestion, you analyze and sort the data so it is ready for the next steps. This process ensures you have a single, reliable repository for all your ai projects.
You need clean and accurate data for successful ai pipeline results. Data cleaning removes errors, fills in missing values, and ensures consistency. You use several techniques to prepare your data for analysis:
| Data Cleaning Technique | Purpose | Use Cases |
|---|---|---|
| Handling missing values | Identify and address missing data | Imputation strategies for critical fields |
| Removing duplicate data | Eliminate redundant entries | Ensuring data accuracy in analysis |
| Standardizing formats | Ensure consistency in data representation | Correcting casing and fixing misspellings |
| Schema and type validation | Confirm data structure | Automatic validation rules |
| Real-time cleansing | Validate data on-the-fly | Immediate analytics for fraud detection |
| Bias and fairness checks | Mitigate systemic biases | Ethical ai model deployment |
You also transform data to improve its quality. You clean messy data, fix errors, and fill in gaps. You change formats to keep everything consistent, such as converting text to numbers. You combine data from multiple sources to create a comprehensive dataset. You aggregate, filter, or summarize information to make it more relevant for ai models. The principle of "Garbage in, garbage out" reminds you that high-quality input leads to reliable results. If you skip these steps, your ai data pipelines may produce poor predictions.
Note: Data processing at this stage sets the foundation for accurate and ethical ai outcomes.
You move to model training and deployment after preparing your data. You collect relevant datasets and explore them for quality. You clean and transform the data again if needed. You use feature engineering to identify key variables that help your model make better predictions.
Here are the main steps in this part of the training pipeline:
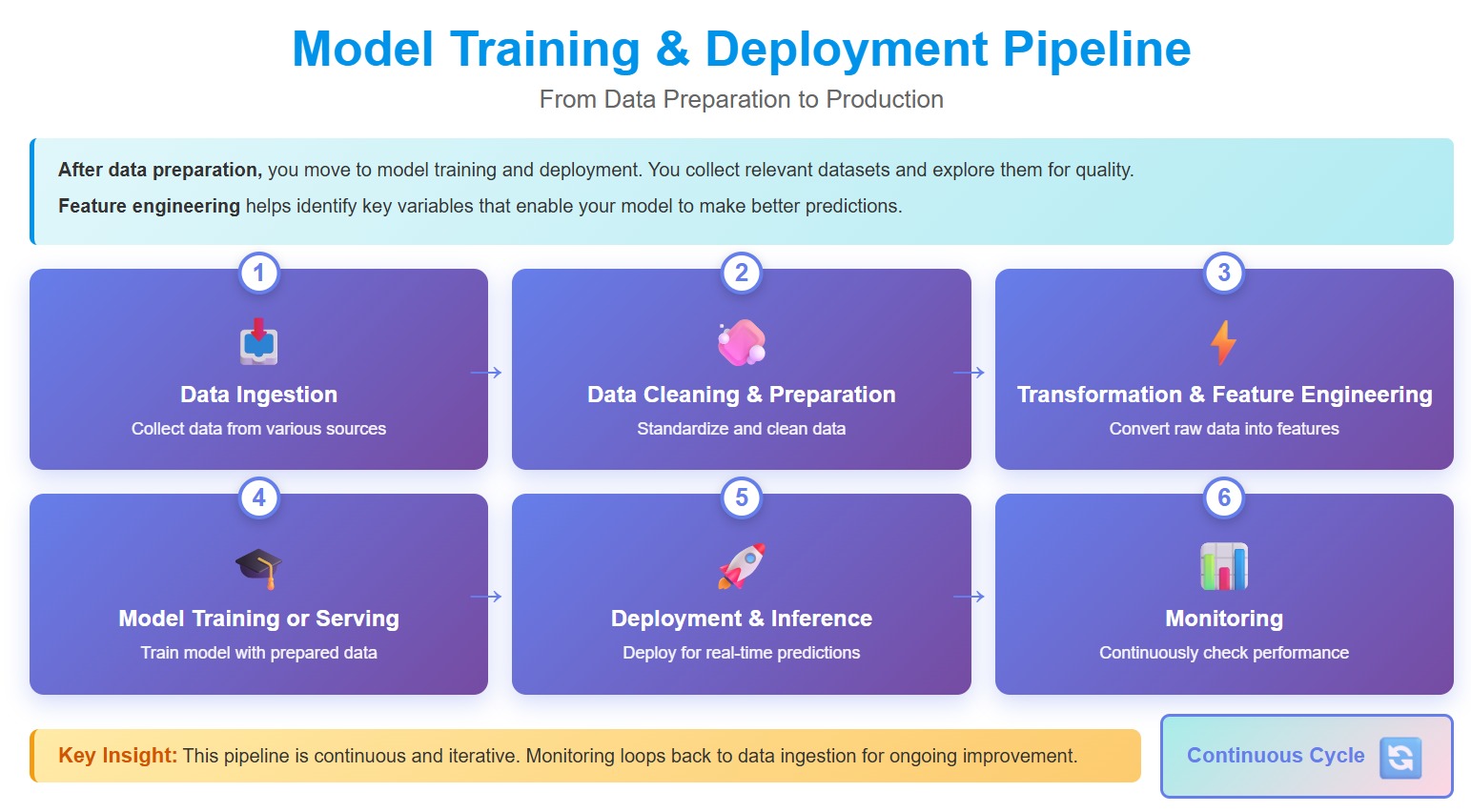
You set up the right infrastructure for deployment. You automate the pipeline to allow seamless updates and changes. You monitor performance and use feedback loops for continuous improvement. You track key performance indicators and set up alerts for deviations. You retrain models regularly to keep them accurate. You also protect your models with strong cybersecurity measures.
| Practice | Description |
|---|---|
| Thorough Validation | You test models in controlled environments before deployment. |
| Continuous Monitoring | You track model performance after deployment to maintain reliability. |
| Performance Tracking and Alerts | You monitor KPIs and set alerts for any issues. |
| Feedback Loops | You collect user feedback to find reliability gaps. |
| Regular Audits | You review model performance against benchmarks. |
| Detecting Model Drift | You watch for changes in data that may affect model accuracy. |
| Model Maintenance Practices | You retrain and update models to keep them relevant. |
| Strong Cybersecurity | You protect models from attacks and unauthorized access. |
| Resilience and Failover Plans | You design systems for high availability and graceful failure handling. |
| Governance and Compliance | You set up frameworks for accountability and reliability. |
For example, a fintech company noticed its fraud detection ai missed new fraud types. Continuous monitoring revealed the problem. The team retrained the model with recent examples, restoring accuracy. This shows why you must monitor and maintain your inference pipeline.
Callout: You ensure reliability and scalability by validating models, monitoring performance, and updating them as needed.
You complete the data pipeline lifecycle by deploying models and keeping them up to date. This approach helps you make accurate predictions and supports business growth.

You build an effective ai data pipeline by connecting many types of data sources. These often include databases, cloud services, and IoT devices. This integration lets you move information smoothly across your systems, which is essential for any ai project. Modern storage solutions help you manage this data efficiently. You can scale up with hybrid or cloud-based storage, so your ai models always have enough space and speed. High-performance technologies like SSDs and NVMe boost data throughput and reduce delays. You can also use tiered storage to balance cost and performance. Caching and prefetching help your ai applications respond quickly, even in real time. Redundant storage nodes and automated failover keep your data safe and available.
You need strong processing and orchestration tools to manage the data pipeline lifecycle. Tools like Kubeflow, Apache Airflow, and Prefect help you automate and monitor each step. These tools handle resource allocation, versioning, and scaling for your ai workflows. For example, a financial company used IBM watsonx Orchestrate to automate customer support, which improved both speed and satisfaction. Orchestration brings speed, reliability, and real-time analytics to your ai data pipeline. You reduce manual errors and speed up deployments. You also ensure that your data processing remains reliable and efficient.
| Benefit | Description |
|---|---|
| Speed and agility | Orchestration reduces manual errors and speeds up deployments. |
| Reliability | Engines manage retries, sequencing, and monitoring for data integrity. |
| Real-time analytics | Tools enable near-real-time analytics and recommendations. |
You gain many benefits by automating your ai data pipeline. Automation lowers labor costs and lets your IT team focus on more valuable projects. You can scale your data pipeline as your business grows, without needing extra staff. For example, a manufacturing company cut data processing time by 40% through automation. A financial institution reached 99.9% data accuracy, which improved reporting and compliance. FanRuan's FineDataLink makes this possible by offering real-time synchronization, low-code setup, and support for over 100 data sources. You can automate data synchronization, improve data quality, and scale your operations with ease. FineDataLink helps you keep your data pipeline efficient and reliable, supporting your business intelligence and ai goals.
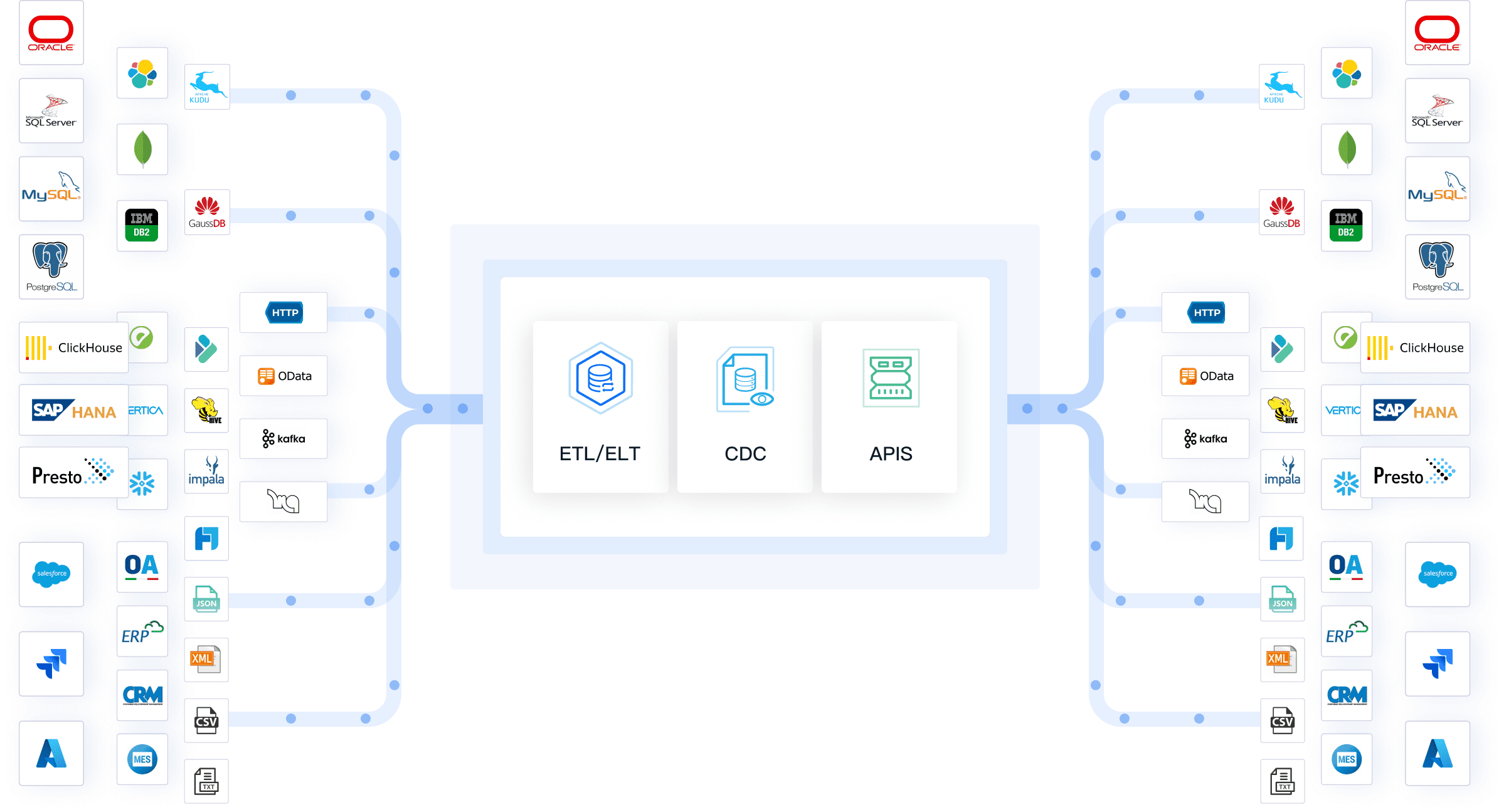
You often face challenges when you try to connect different systems and sources in your ai data pipeline. FineDataLink helps you solve these problems by offering a modern platform for data integration. You can connect over 100 types of data sources, including databases, cloud services, and APIs. FineDataLink lets you synchronize data in real time, which keeps your ai models up to date and reduces delays. You do not need to write code to set up API connections, so you save time and avoid errors.
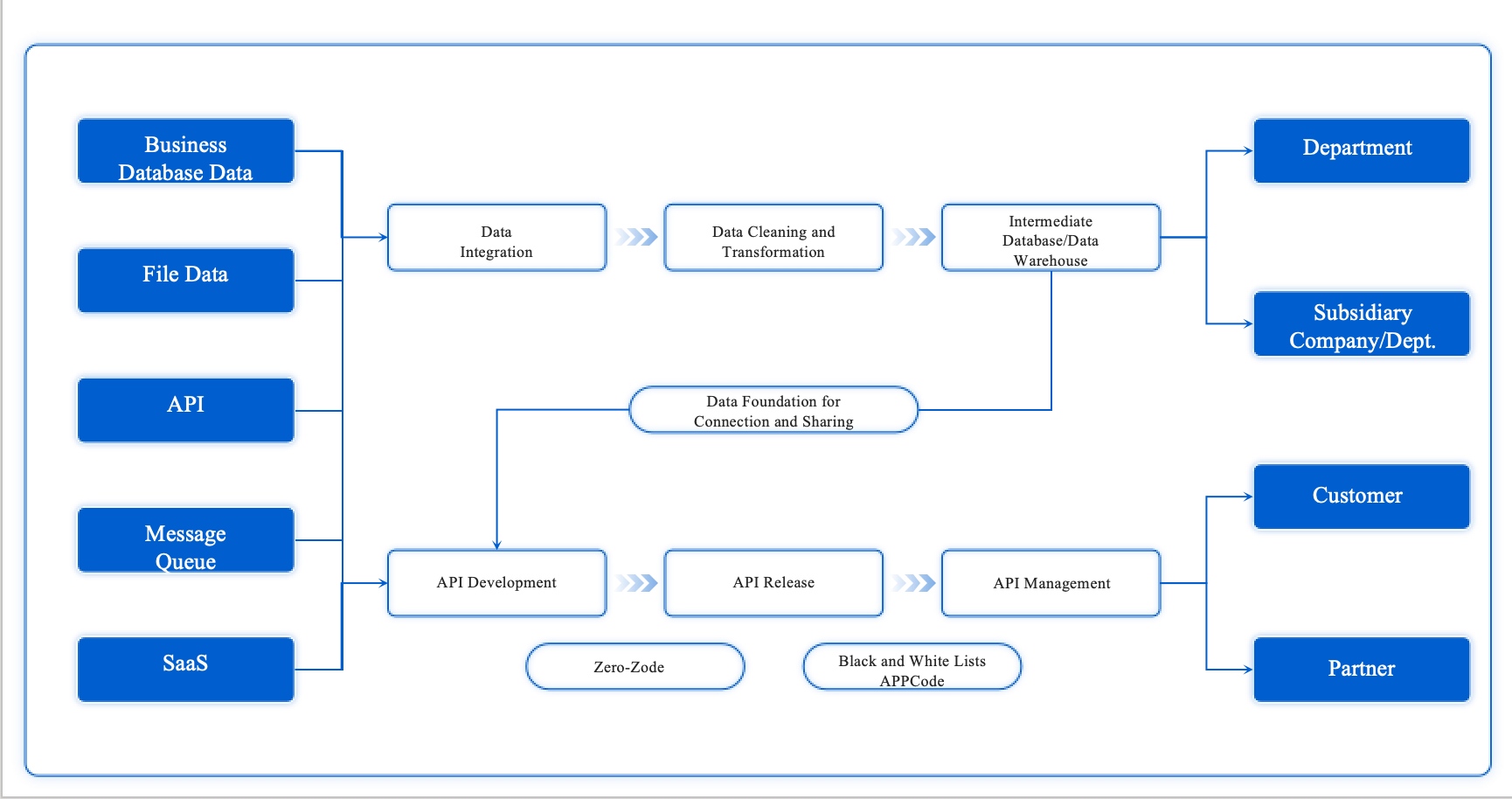
Here is how FineDataLink’s API connectivity improves your ai data pipeline performance:
| Evidence Description | Impact on AI Data Pipeline Performance |
|---|---|
| Enables secure, convenient, and code-free cross-domain data transmission | Enhances data sharing and interconnectivity |
| Supports various data sources, including API-based data | Facilitates integration of diverse data for AI applications |
| Real-time data synchronization | Maintains data freshness and reduces latency in AI applications |
You can use FineDataLink to build a strong feature pipeline, manage your data processing, and support both your ai training pipeline and ml pipeline. This approach helps you create a reliable foundation for your ai projects.
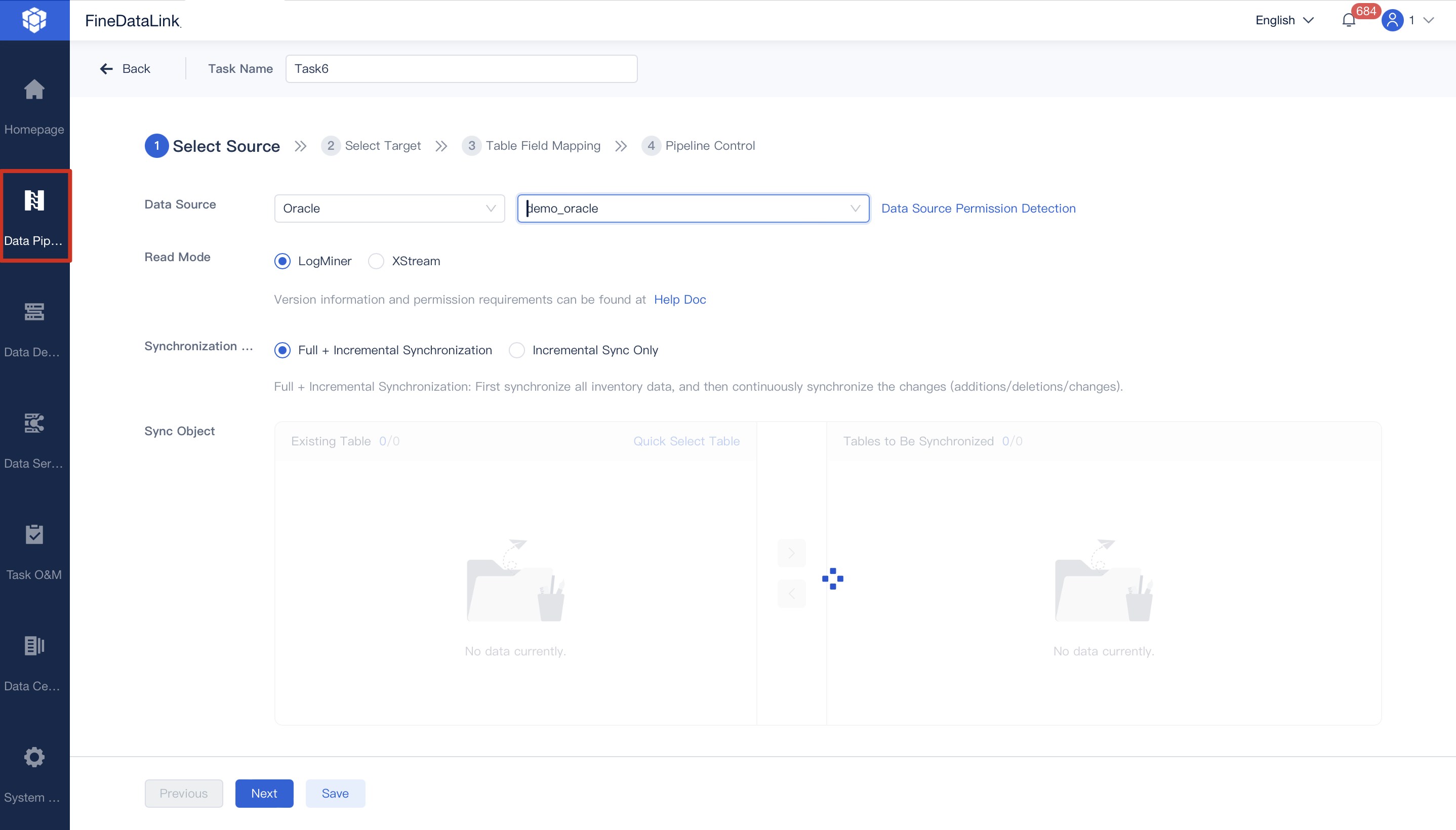
You want to make business intelligence easier for everyone in your company. FineChatBI gives you a natural language interface, so you can ask questions and get answers from your data without needing technical skills. You can connect FineChatBI to your ai data pipelines, but you need to set up a solid foundation first. This means you must define your metrics, manage user permissions, and clarify what your data means. When you do this, FineChatBI becomes a powerful tool for exploring data and making decisions.
You can use FineChatBI to analyze results from your ai pipeline, review outputs from your feature pipeline, and support your business with fast, accurate insights.

You can see the impact of these solutions in real business settings. NTT DATA Taiwan used FanRuan’s tools to build a unified data platform. They integrated data from ERP, POS, and CRM systems using ETL processes. This platform allowed them to visualize data, support decision-making, and improve operational efficiency. Employees at all levels could use self-service analytics, which made it easier to find insights and act quickly. This real-world example shows how you can use ai data pipelines to drive digital transformation and support sustainable growth.

Tip: When you combine strong data integration with user-friendly analytics, you empower your team to make smarter decisions and unlock the full value of your data.
You might wonder how ai pipelines compare to traditional data pipelines. The main differences come from the way each handles data and supports business goals.
Here is a table that shows how workflow automation and adaptability differ:
| Feature | AI-Driven Pipelines | Traditional Pipelines |
|---|---|---|
| Workflow Automation | High, automates processes | Low, manual processes dominate |
| Adaptability | High, adjusts to new data formats | Low, struggles with new formats |
| Human Intervention | Minimal, focus on analysis | High, needs constant oversight |
When you use ai-driven pipelines, you gain several important benefits for your business.
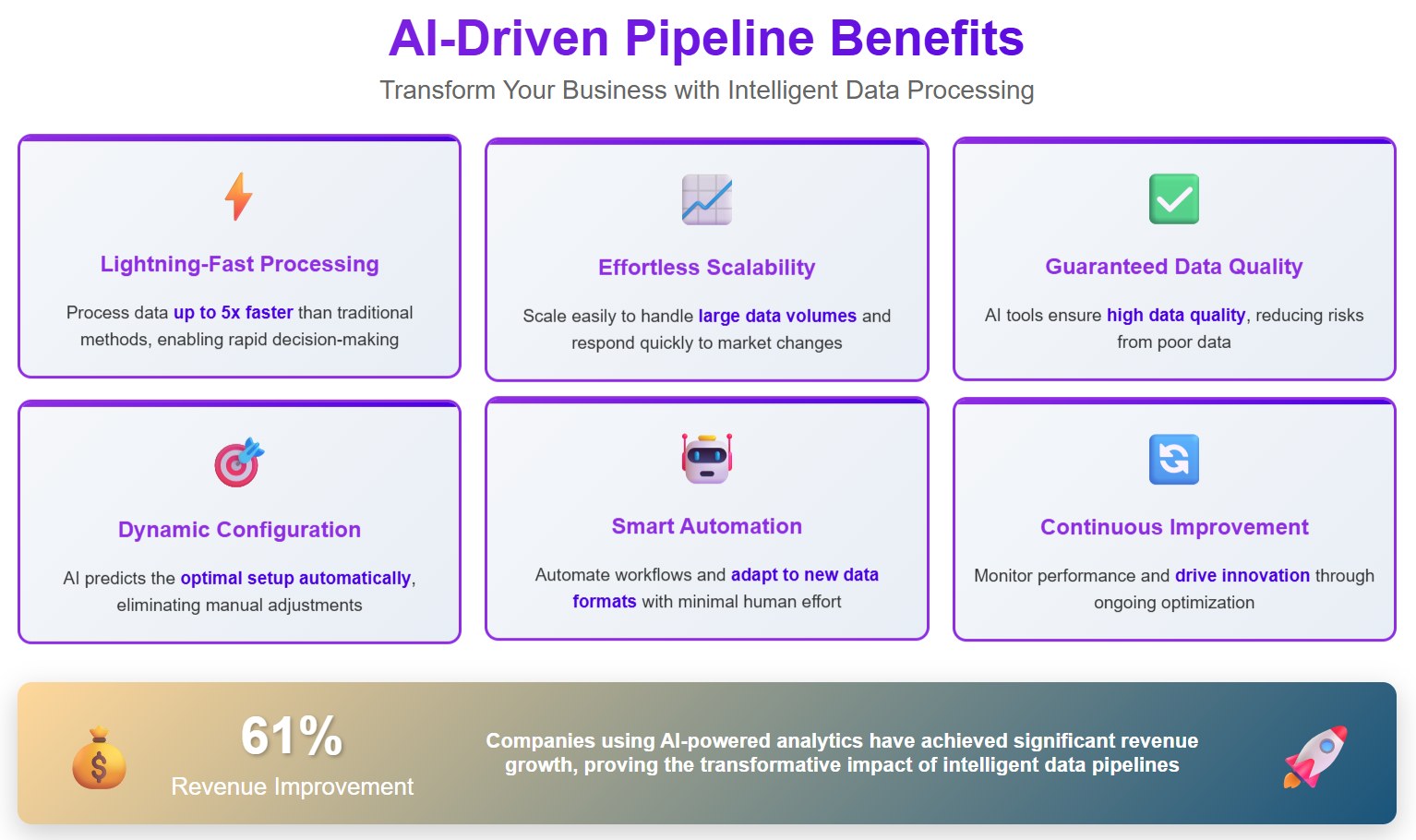
Here is a table that highlights more benefits:
| Feature | AI-Driven Pipelines | Traditional Pipelines |
|---|---|---|
| Manual Effort | Reduced through automation | High due to manual processes |
| Resilience | Improved adaptability | Limited, often rigid |
| Time-to-Insight | Real-time insights | Slower, manual intervention |
| Trustworthiness | AI suggestions + validation | Manual checks only |
Tip: Ai-driven pipelines let you focus on analysis and innovation, not just moving data from place to place.
You rely on ai data pipelines to automate decision-making, optimize performance, and ensure data quality. The table below highlights key benefits:
| Key Benefit | Description |
|---|---|
| Efficient Decision-Making | Automates data collection and delivery for faster insights |
| Optimization | Improves accuracy and scalability, boosting ROI |
| Enhanced Data Movement | Enables predictive analytics and better decisions |
| Importance of Data Quality | Requires thorough cleaning and robust infrastructure |
FanRuan and FineChatBI help you access actionable insights with natural language queries, smart reporting, and AI-powered decision support. You can explore these tools to make data analysis easier and more reliable.

The Author
Lewis
Senior Data Analyst at FanRuan
Related Articles

What Is a Data Agent? A Practical Beginner’s Guide to How It Works
A data agent is one of the easiest ways to make business data feel more accessible. Instead of opening dashboards, writing SQL, or asking an analyst for help, you can ask a question in plain language and get an answer ba
Saber CHEN
Apr 02, 2026

Create AI Dashboards Instantly Without Coding
Create an ai dashboard instantly without coding. Connect data, analyze, and build dashboards in minutes using AI tools for fast, secure insights.
Lewis
Dec 29, 2025

FineChatBI vs Mercury Labs MLX Dashboard Performance in 2026
Compare FineChatBI and Mercury Labs MLX dashboard performance, speed, features, and integration to choose the best mlx dashboard for your business in 2026.
Saber
Dec 22, 2025



