A CMMS Dashboard should do one job exceptionally well: help maintenance and operations leaders make faster, better decisions with less guesswork. If your dashboard only reports how many work orders were opened or closed, it is tracking activity, not improving performance.
For maintenance managers, plant leaders, and reliability teams, the real value of a CMMS dashboard is operational clarity. It should show where downtime risk is rising, which assets are draining budget, where backlog is becoming dangerous, and whether preventive maintenance is actually reducing failures. When designed correctly, a CMMS dashboard shortens response time, improves planning accuracy, and reduces avoidable downtime.
The problem in most organizations is not lack of data. It is that too much maintenance data is presented without context, prioritization, or role relevance. A supervisor, an operations director, and a reliability engineer do not need the same screen. They need different views of the same maintenance reality, aligned to the decisions they own.
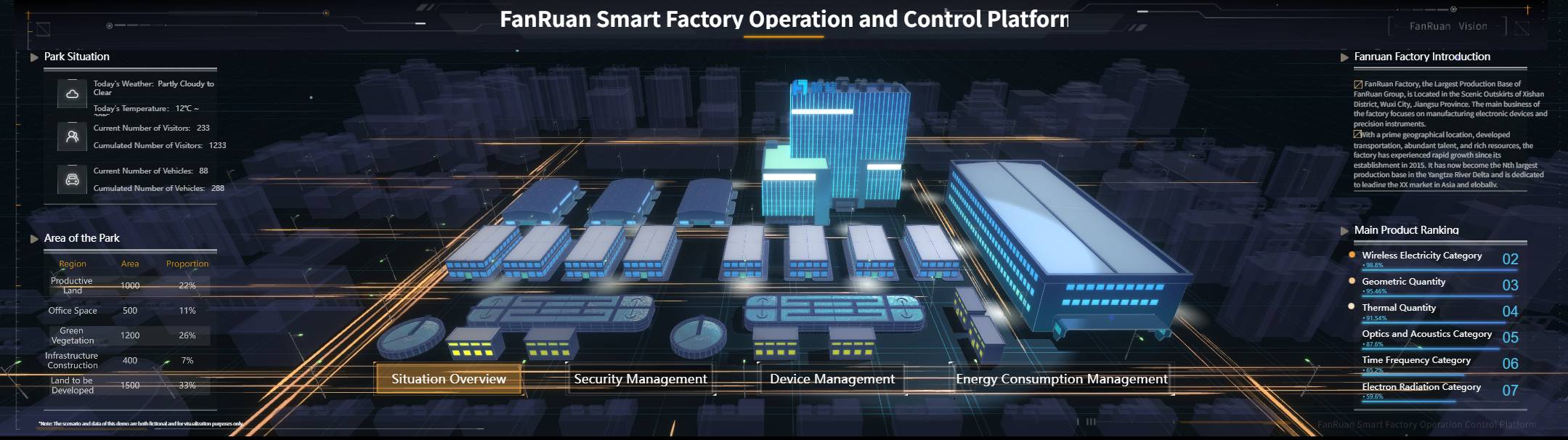
All the dashboards in this article are created by dashboard software: FineBI
A useful CMMS Dashboard is not a digital wall of charts. It is a decision-support system for daily, weekly, and monthly maintenance management.
Many dashboards stop at surface-level reporting:
These numbers are not useless, but on their own they rarely answer the questions leaders actually ask:
A decision-oriented dashboard translates raw system transactions into operational signals. It moves the team from “what happened” to “what needs action.”
When a CMMS dashboard is built around decisions, three things improve quickly:
This is especially important in environments where maintenance delays directly affect throughput, service levels, safety, or customer commitments.
One of the biggest dashboard design mistakes is giving every user the same view. That creates clutter for some users and missing context for others.
A role-based CMMS dashboard works because it aligns metrics to decisions:
The underlying data can be shared. The presentation should not be.
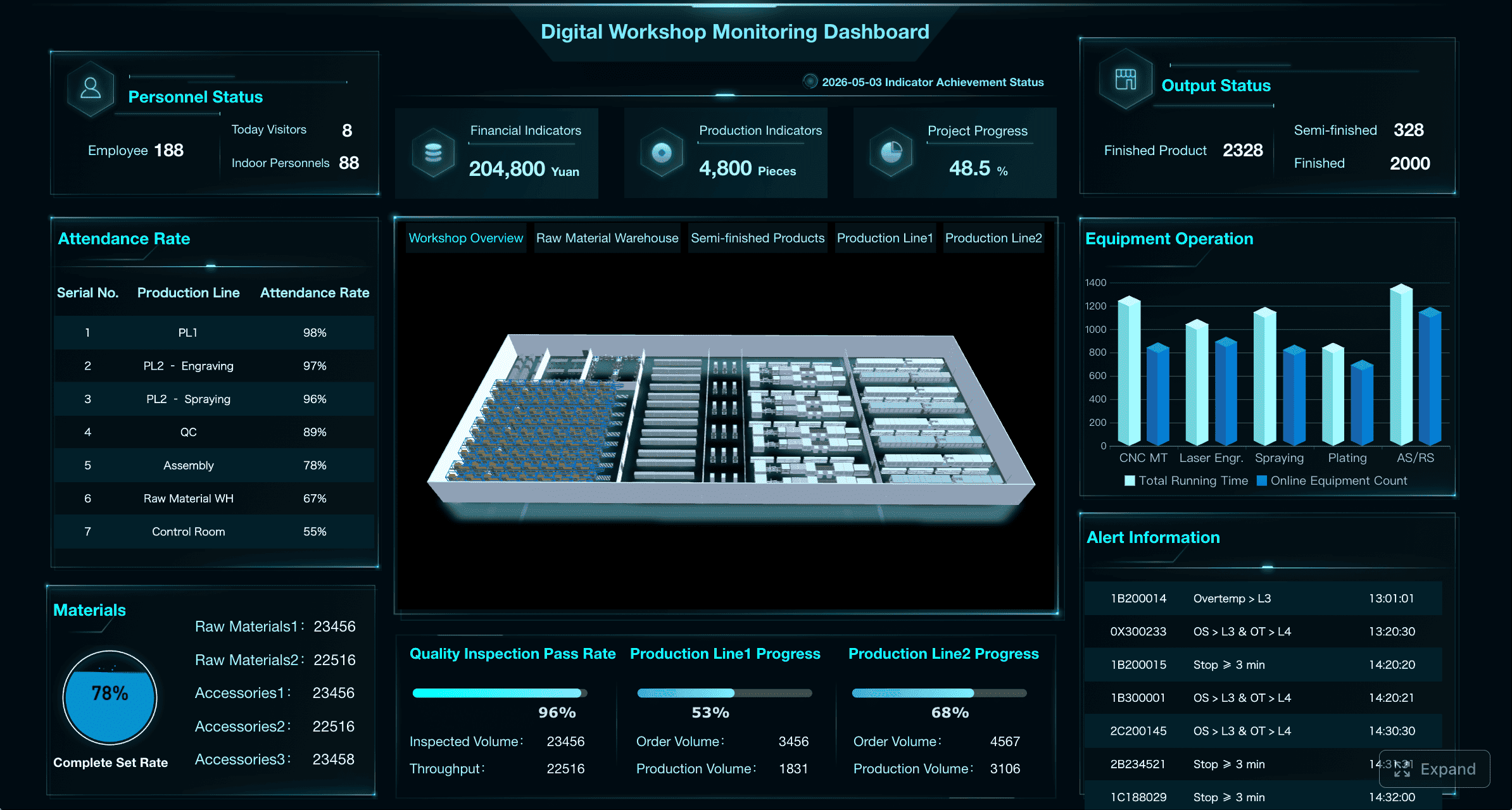
A strong CMMS Dashboard needs a focused KPI structure. Below are the core elements that turn maintenance data into action.
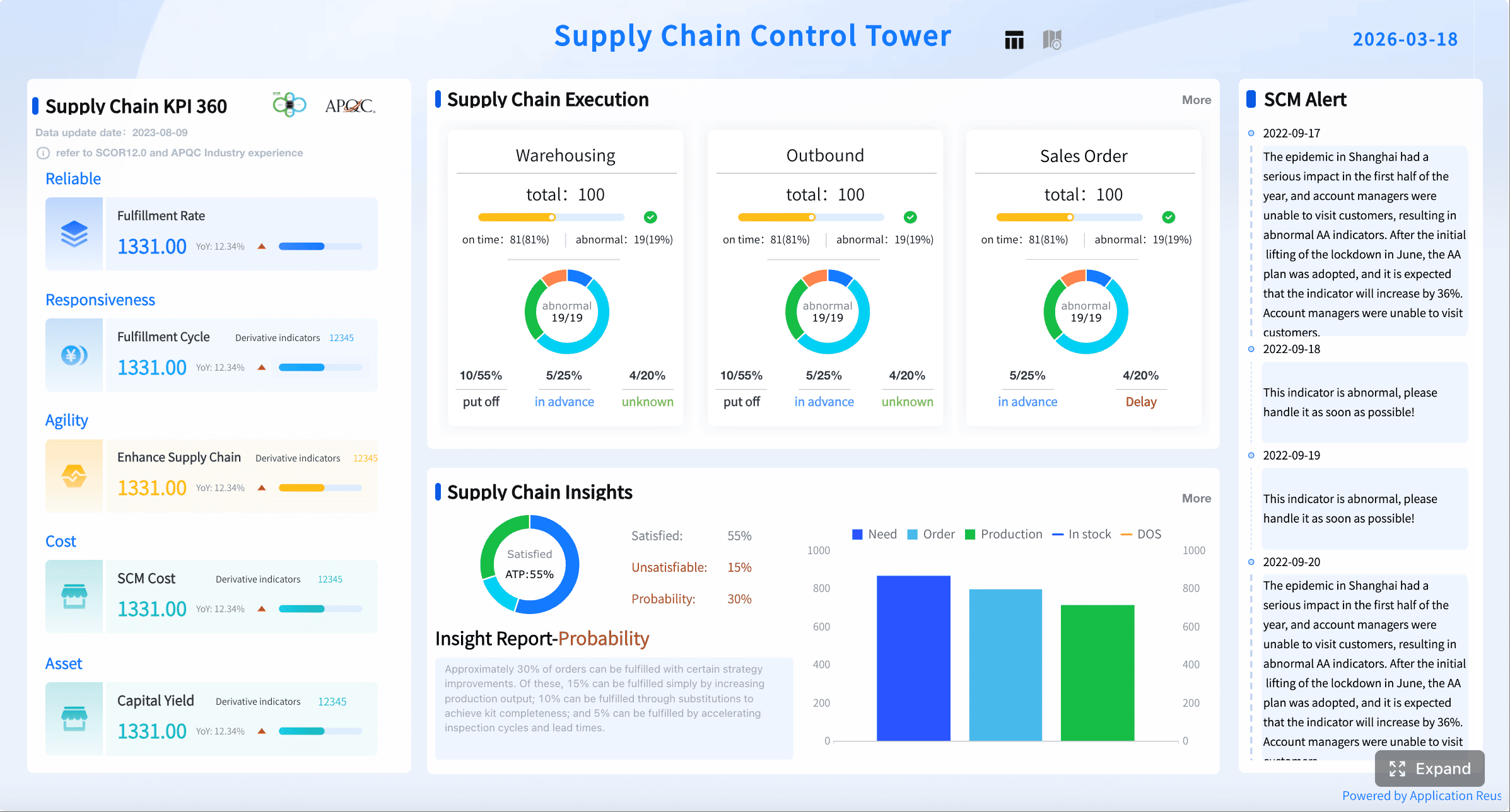
The first job of a CMMS dashboard is to expose asset risk before it becomes an outage.
MTBF is one of the clearest indicators of reliability trend. If MTBF is rising, the asset is staying online longer between failures. If it is falling, the maintenance strategy may be losing effectiveness.
MTBF becomes more useful when viewed by:
A single MTBF number for the whole plant is too broad to guide action.
Unplanned downtime is the metric operations leaders care about most because it connects maintenance performance to output loss. Your dashboard should show:
This makes it easier to isolate where reliability problems are hurting production the most.
Repeat failures often reveal weak corrective action. If the same motor, pump, valve, or conveyor keeps failing, the issue may be poor root cause analysis, wrong spare parts, poor installation, or a planning gap.
Overlaying repeat failures with asset criticality is powerful. A frequently failing non-critical asset may be inconvenient. A moderately failing critical asset can be a major business risk.
A CMMS Dashboard should also tell you whether the maintenance process itself is healthy.
Backlog is not just a count of open jobs. It is a capacity and risk indicator. The most useful backlog view breaks open work into:
A growing backlog in high-priority or critical-asset work is an early warning signal that planning capacity or labor allocation needs attention.
These metrics show whether the team is delivering work as intended.
A team may close many jobs but still have poor schedule discipline if urgent work constantly disrupts the plan.
Wrench time highlights execution efficiency. Low wrench time can point to poor parts staging, too much travel, unclear job plans, or excessive admin burden.
Emergency work ratio shows how much of your maintenance effort is spent firefighting. If emergency work consumes too much capacity, planned work suffers, backlog grows, and failure rates usually increase later.
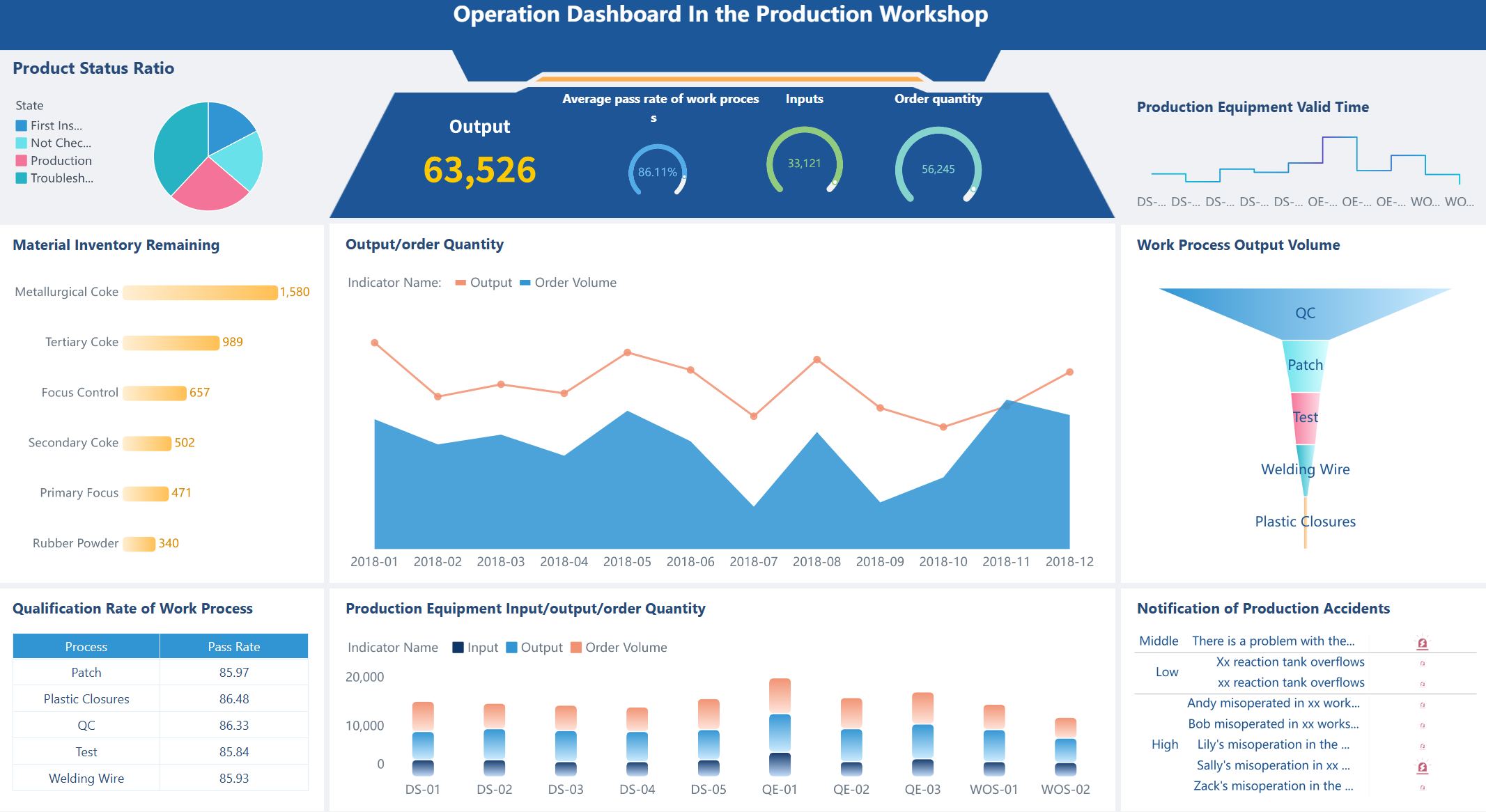
Maintenance decisions are never just about reliability. They are also about cost control and resource efficiency.
This KPI helps identify assets that consume disproportionate spend. When an asset shows repeated high maintenance cost over multiple periods, leaders can make evidence-based repair-versus-replace decisions.
This view becomes stronger when paired with:
A maintenance team can look busy while still operating inefficiently. Labor utilization helps assess whether the available workforce is aligned to workload. Overtime patterns show whether the system is being stretched due to poor planning, chronic breakdowns, or under-resourcing.
Persistent overtime is often a symptom, not the root problem.
Parts visibility is essential for planning credibility. If planners schedule work but critical parts are unavailable, schedule compliance collapses.
Your dashboard should flag:
This is where maintenance, storeroom, and procurement performance intersect.
The most effective CMMS Dashboard is role-specific. Each audience should see the same operational truth through a decision lens that matches their responsibility.
Maintenance managers need a dashboard that helps them run the function day to day and week to week.
Their ideal view should focus on:
This dashboard should answer practical management questions:
Operations leaders are not looking for maintenance detail for its own sake. They want to understand production risk, service exposure, and cost impact.
Their view should focus on:
This lets operations leaders engage with maintenance using business language, not just maintenance language.
Typical decisions supported by this view include:
Reliability engineers and planners need a deeper analytical layer than frontline managers.
Their dashboard should focus on:
This is the audience most likely to use drill-down analysis. They need to move from summary to root cause, then translate findings into revised maintenance strategy.
Custom dashboards fail when teams treat them as storage space for every available metric. The goal is not to display more data. The goal is to reduce decision friction.
Before adding any chart, answer three questions:
This simple discipline prevents dashboard bloat. If a metric has no action owner and no review cadence, it probably does not belong on the main screen.
A seasoned consultant will usually insist on a metric map before dashboard design begins. That map should define:
This creates a shared data language and avoids endless debates over KPI definitions later.
For most organizations, seven views are enough to cover the daily and weekly maintenance decision cycle.
A high-level snapshot of reliability, backlog, PM compliance, and maintenance cost.
Focus on availability, MTBF, repeat failures, and top risk assets.
Track open work, aging, priorities, and completion trends.
Show PM schedule adherence, overdue PMs, and PM completion rates.
Surface major downtime events, causes, trends, and impacted areas.
Monitor maintenance spend by asset, department, site, or line.
Highlight stockouts, low-stock critical spares, and parts delaying work.
[Insert Dashboard Demo Here: Seven-tab CMMS dashboard navigation with executive summary, asset health, work orders, PM, downtime, cost, and inventory views]
Dashboards become actionable when they emphasize exceptions, not just totals.
Best practice is to configure:
This helps teams notice what needs action first and avoids wasting review time on stable metrics.
Exception-based reporting is especially valuable for distributed operations where leaders cannot manually inspect every metric every day.
Here are four practical steps to build a CMMS dashboard that users will actually trust and use:
Standardize KPI definitions before design
Define downtime, backlog, on-time completion, emergency work, and PM compliance consistently across sites and teams.
Design one primary dashboard per role
Avoid trying to satisfy executives, managers, planners, and technicians on one screen.
Prioritize trend plus drill-down, not just current status
A single number lacks direction. A trend with drill-down tells users whether performance is improving and why.
Review adoption and actionability every month
If a widget is never used or never triggers action, remove or redesign it.
[Insert Dashboard Demo Here: Alert-enabled dashboard with red/yellow/green thresholds and drill-down from KPI card to asset-level details]
Even modern maintenance organizations often weaken dashboard value with avoidable design mistakes.
When every metric looks equally important, none of them gets attention. Too many widgets create scanning fatigue and slow decision-making.
A dashboard should prioritize the few metrics most closely tied to risk, capacity, reliability, and cost.
Executives do not need raw technician-level task views. Frontline supervisors do not need portfolio-level cost rollups without operational detail.
Mixing these layers on one screen creates confusion and distracts each audience from the actions they need to take.
If your dashboard only reports what already happened, it becomes a historical summary, not a management tool.
Lagging metrics like monthly downtime and spend must be paired with leading indicators such as:
These are the signals that help teams intervene earlier.
If one site defines downtime differently from another, or if backlog includes different work types by team, comparisons become unreliable.
A CMMS dashboard is only as credible as the governance behind it. Standard definitions are not bureaucracy. They are the foundation of trust.
[Insert Dashboard Demo Here: Side-by-side example of cluttered dashboard versus simplified role-based dashboard with prioritized KPIs]
A CMMS Dashboard should evolve with your maintenance maturity. What matters in a reactive environment is different from what matters in a reliability-led operation.
At least once a month, review each dashboard metric and ask:
If the answer is no repeatedly, the metric may not deserve prime dashboard space.
A dashboard is only successful if it correlates with better performance in the field.
Look for evidence that dashboard use aligns with:
If trends look good on screen but outcomes are not improving, the issue may be bad data quality, weak threshold design, or poor action follow-through.
As maintenance programs improve, dashboard needs change.
Early-stage teams may focus on:
More mature teams may shift toward:
Dashboards should be treated as living management tools, not fixed reporting artifacts.
Building this manually is complex; use FineBI to utilize ready-made templates and automate this entire workflow.
A high-performing CMMS Dashboard requires more than charts. It needs structured KPI logic, role-based views, drill-down analysis, exception alerts, and repeatable review workflows. Trying to maintain all of that manually in spreadsheets or static reporting tools quickly creates inconsistency, delay, and low adoption.
FineBI helps enterprise teams turn maintenance data into decision-ready dashboards without forcing every request through IT. With self-service analysis, visual dashboard building, drill-down capability, personalized views, and collaborative sharing, teams can build dashboards that fit maintenance managers, operations leaders, and reliability teams without overwhelming users.
FineBI is especially effective when you need to:
Instead of stitching together static reports, teams can use FineBI to combine analysis, interpretation, and action in one environment. That makes it easier to move from seeing a maintenance issue to assigning ownership and tracking improvement over time.
If your current CMMS dashboard is heavy on data but light on decisions, the next step is not adding more widgets. It is redesigning the reporting workflow around action. FineBI gives you a faster way to do that with scalable dashboard templates, self-service analytics, and automation built for enterprise decision support.
The most useful KPIs are the ones that expose risk, capacity, and cost, such as MTBF, unplanned downtime, backlog aging, emergency work ratio, PM compliance, and maintenance cost by asset. These metrics help teams decide where to act, not just report what happened.
Different roles make different decisions, so they need different metrics and levels of detail. A maintenance manager may need backlog and schedule compliance, while an operations leader cares more about downtime impact and cost trends.
A well-designed dashboard highlights early warning signs like falling MTBF, repeat failures, overdue preventive work, and growing emergency work. That visibility helps teams intervene sooner before minor issues turn into production outages.
Activity metrics show volume, such as work orders opened or hours logged, but they do not explain whether maintenance performance is improving. Decision-making metrics add context by showing reliability, backlog risk, execution quality, and cost patterns that guide action.
Review frequency depends on the metric and the role, but most operational KPIs should be checked daily or weekly, while broader cost and reliability trends are often reviewed monthly. The key is matching the review cadence to the decision being made.

The Author
Yida Yin
FanRuan Industry Solutions Expert
Related Articles
What Is OEE (Overall Equipment Effectiveness)? How to Calculate It Correctly and Avoid Misleading Results
Learn what Overall Equipment Effectiveness (OEE) is, how to calculate it correctly, and how to avoid misleading results.
Yida Yin
May 11, 2026

Building an SPC Dashboard: 7 Must-Track Metrics for Statistical Process Control
Learn the 7 essential SPC dashboard metrics for manufacturing quality control, including process stability, capability, and defect rate.
Yida Yin
May 11, 2026

Predictive Maintenance Dashboard: 9 Metrics Enterprise Teams Should Monitor Before Equipment Fails
A predictive maintenance dashboard helps enterprise teams spot equipment risk before it turns into downtime, scrap, safety exposure, or missed production targets. For plant leaders, reliability engineers, and maintenance
Yida YIn
Jan 01, 1970



