Smart Manufacturing
Saber Chen
2026 Mei 10
Predictive maintenance bukan lagi proyek eksperimental bagi pabrik modern. Bagi manajer operasional, maintenance manager, dan tim IT/OT, ini adalah cara langsung untuk menekan downtime tidak terencana, mengurangi biaya perbaikan mendadak, dan menjaga throughput tetap stabil. Dalam konteks machine learning in manufacturing, pendekatan ini memungkinkan tim mendeteksi gejala kegagalan mesin lebih awal dari pola data sensor, histori work order, dan konteks operasi aktual.
Jika saat ini pabrik Anda masih bergantung pada preventive maintenance berbasis jadwal atau reactive maintenance setelah mesin rusak, masalah yang biasanya muncul adalah:
Panduan ini membahas bagaimana machine learning in manufacturing diterapkan untuk predictive maintenance, KPI yang wajib dipantau, arsitektur data yang dibutuhkan, serta langkah implementasi dari pilot sampai skala produksi.
Predictive maintenance adalah pendekatan perawatan yang memprediksi kemungkinan kegagalan aset sebelum kerusakan benar-benar terjadi. Tujuannya bukan sekadar menjadwalkan servis rutin, tetapi menentukan kapan intervensi paling tepat berdasarkan kondisi aktual mesin.
Perbedaannya dengan pendekatan lain cukup jelas:
Dalam manufaktur, pendekatan ini sangat bernilai ketika perusahaan menghadapi:
Machine learning berperan dengan mengenali pola yang sulit dilihat secara manual. Misalnya, kombinasi kenaikan temperatur kecil, perubahan vibrasi tertentu, dan fluktuasi arus motor bisa menjadi sinyal awal bahwa bearing atau komponen tertentu sedang menuju kegagalan. Sistem kemudian dapat memberi peringatan lebih dini agar tim maintenance bertindak sebelum breakdown terjadi.
Pendekatan ini paling relevan ketika perusahaan memiliki:
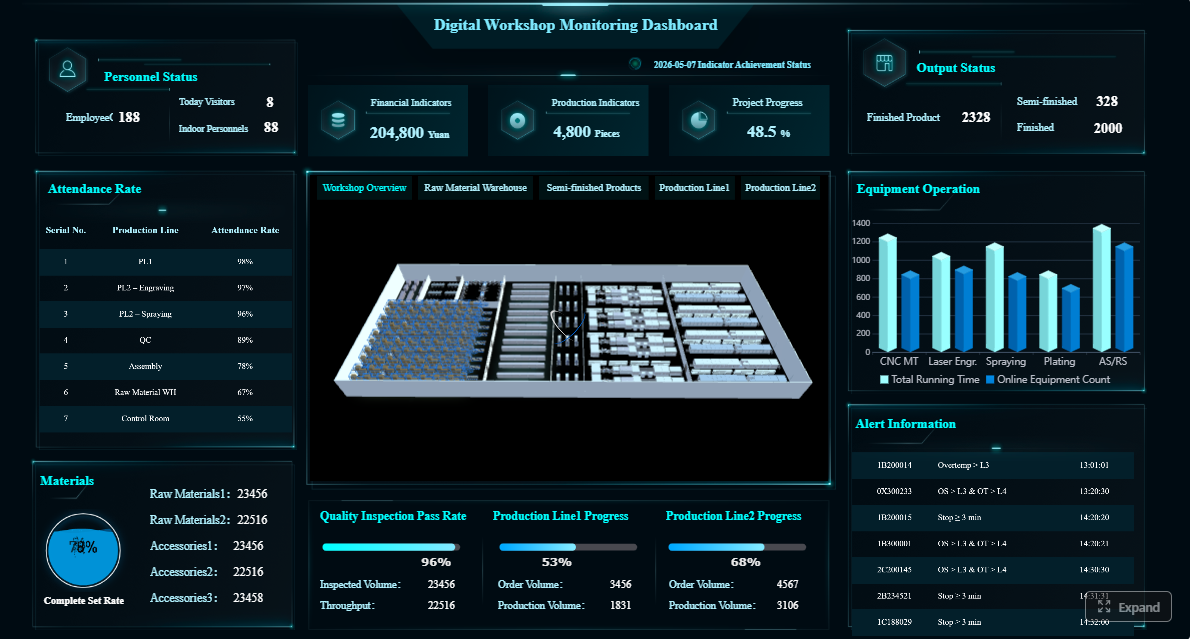 Klik Untuk Mencoba Dashboard FineBI
Klik Untuk Mencoba Dashboard FineBI
Keberhasilan predictive maintenance tidak bisa diukur hanya dari akurasi model. Program yang efektif harus menunjukkan dampak operasional, finansial, dan adopsi di lapangan. Berikut adalah KPI utama yang perlu dipantau.
Downtime tidak terencana biasanya menjadi KPI pertama yang diperhatikan eksekutif pabrik karena dampaknya langsung ke output. Namun MTBF dan MTTR memberi gambaran lebih dalam: apakah aset memang makin andal, dan apakah tim bisa memulihkan kondisi lebih cepat saat insiden tetap terjadi.
Dari sudut pandang bisnis, predictive maintenance harus menunjukkan nilai ekonomi yang nyata, bukan sekadar dashboard yang terlihat canggih.
Bagi pimpinan operasi, KPI finansial sering menjadi dasar keputusan perluasan proyek ke lini atau pabrik lain. Karena itu, baseline sebelum implementasi harus dicatat dengan disiplin.
Model yang bagus bukan model dengan angka akurasi umum tertinggi, tetapi model yang menghasilkan keputusan operasional yang dapat dipercaya.

Tanpa arsitektur data yang rapi, inisiatif machine learning in manufacturing biasanya berhenti di tahap proof of concept. Predictive maintenance membutuhkan data lintas sistem yang konsisten, tersinkronisasi, dan dapat diakses secara aman.
Program predictive maintenance yang kuat biasanya menggabungkan tiga kategori data utama.
Data ini menjadi fondasi untuk mendeteksi perubahan perilaku aset.
Contohnya meliputi:
Semakin kritis aset, semakin penting kualitas sensor dan frekuensi sampling yang sesuai dengan karakteristik failure mode.
Data sensor saja tidak cukup. Tim juga memerlukan konteks perawatan untuk memahami apa yang benar-benar terjadi pada mesin.
Sumber umumnya meliputi:
Data ini membantu proses pelabelan, validasi model, dan interpretasi output.
Banyak anomali sebenarnya dipengaruhi oleh cara mesin digunakan, bukan murni kerusakan komponen.
Contoh data konteks:
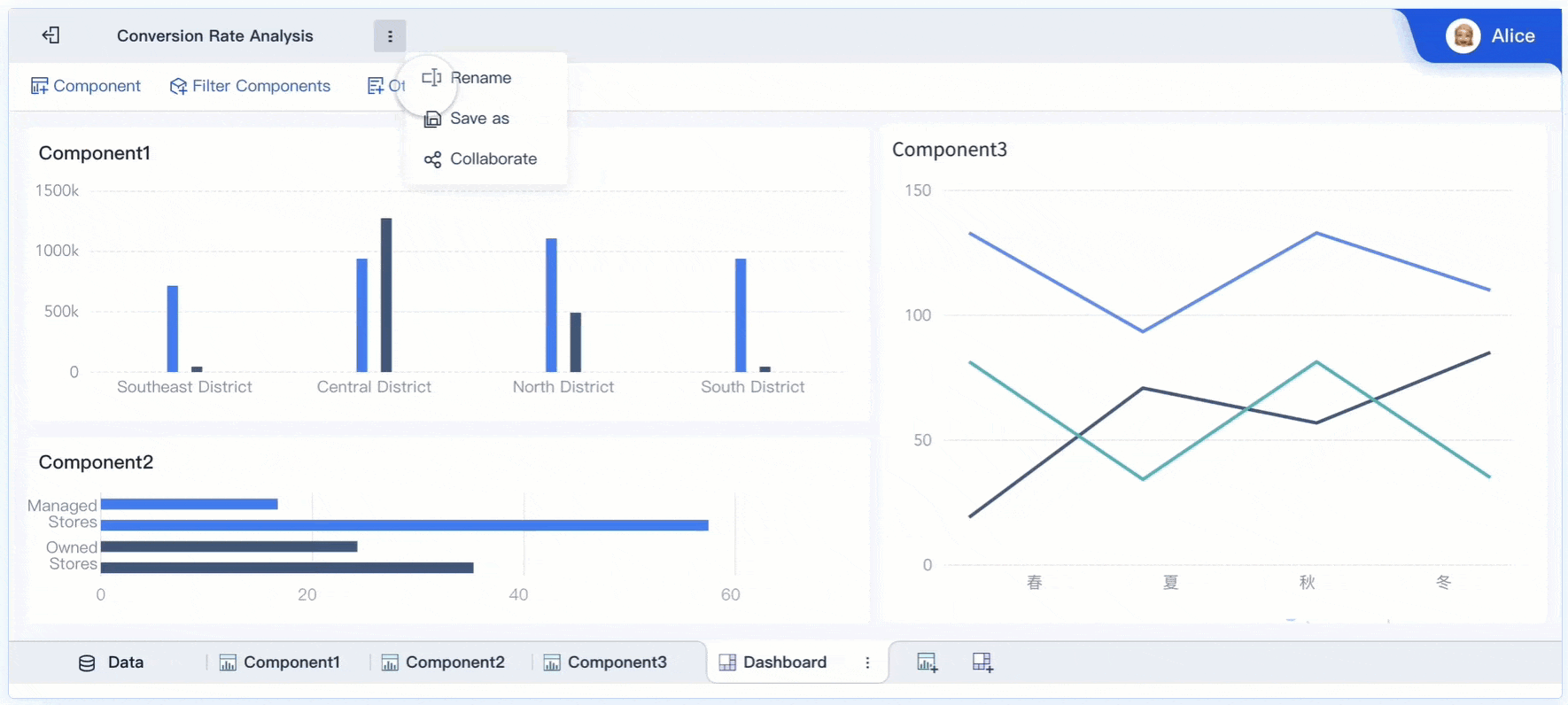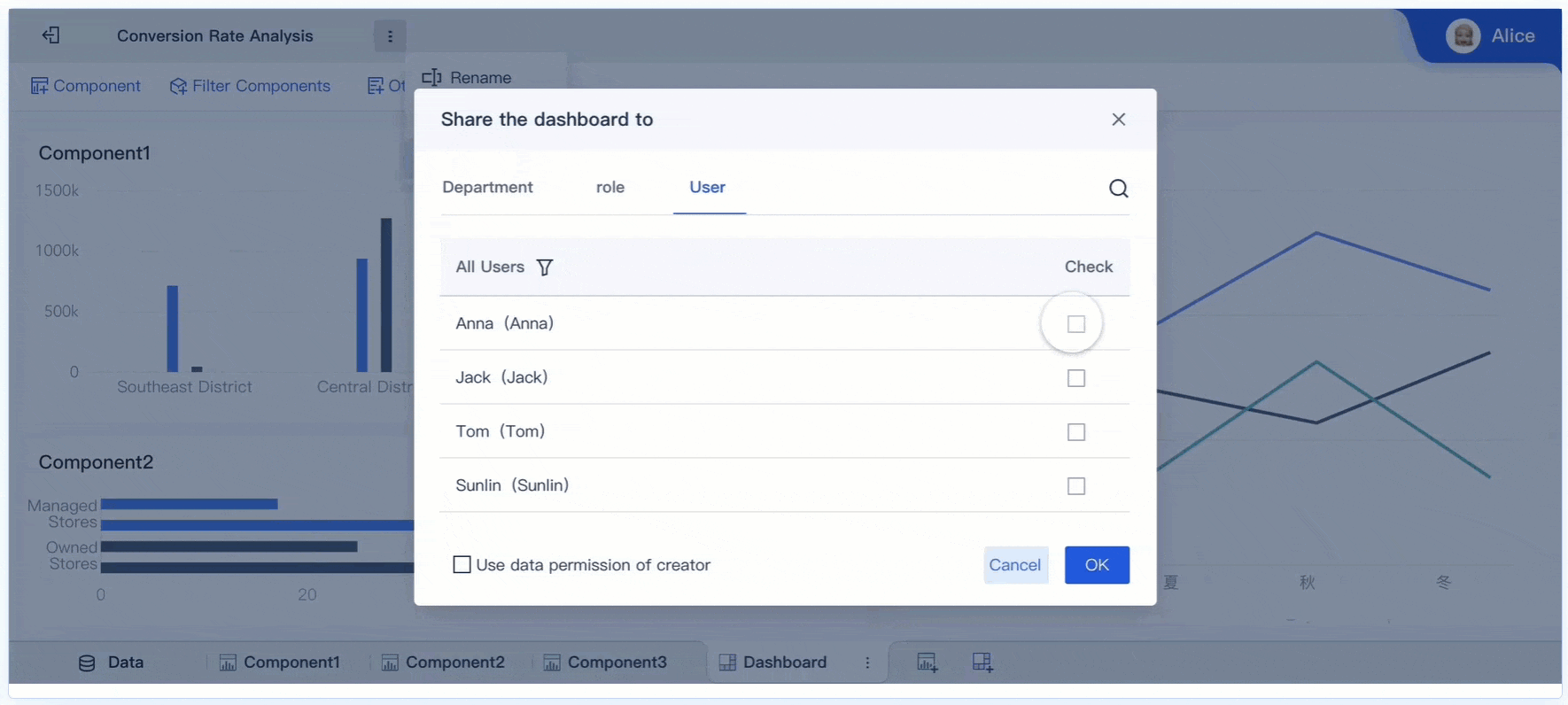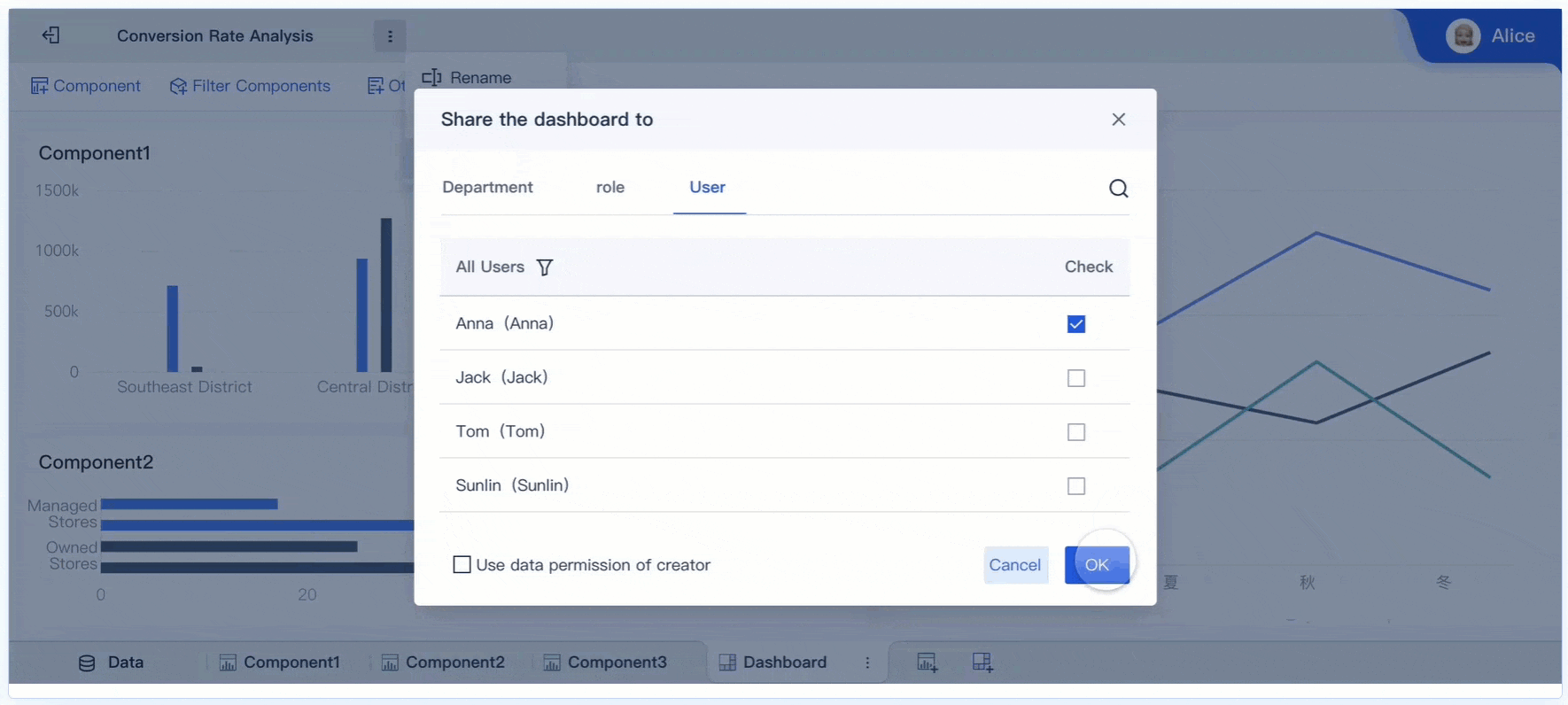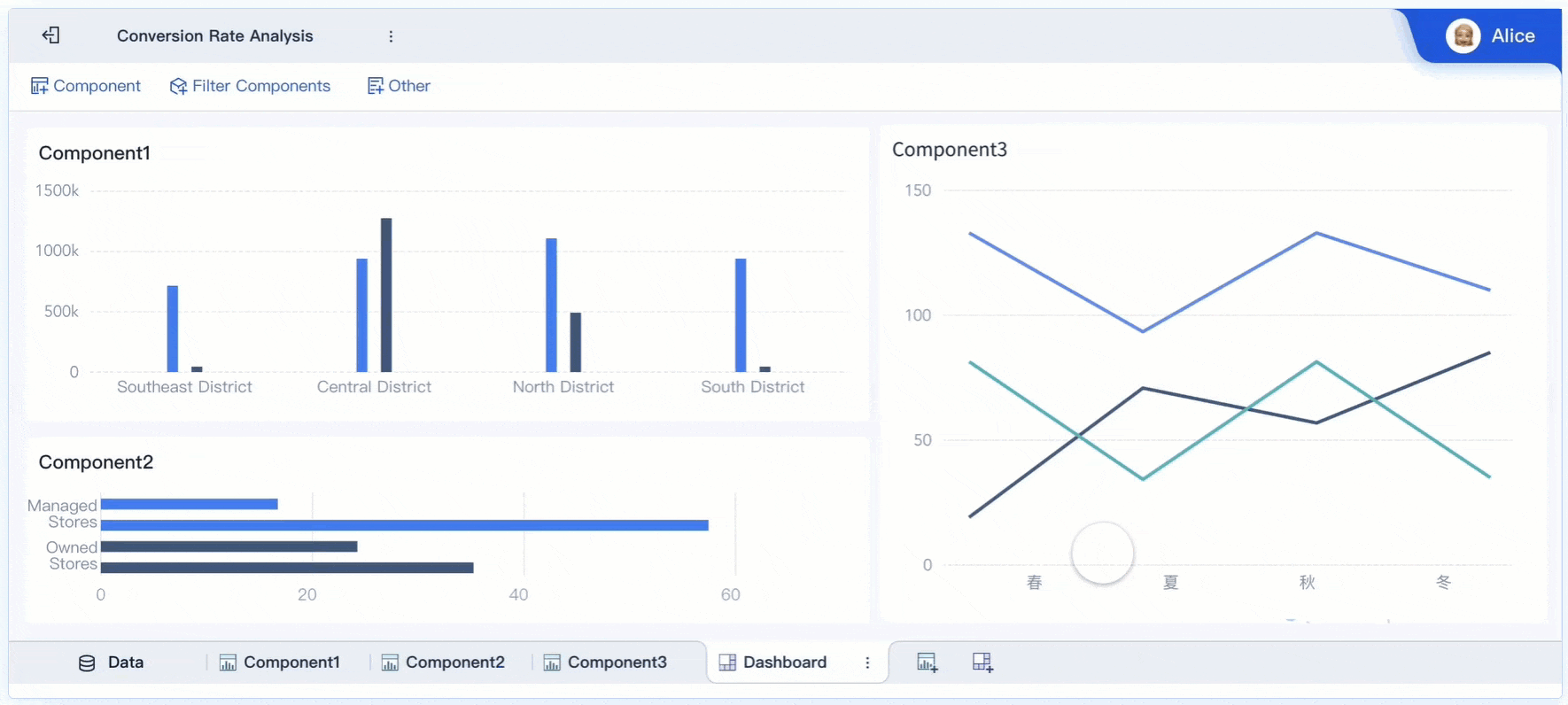
Arsitektur data yang baik harus mampu memindahkan data dari lantai produksi menjadi insight yang bisa ditindaklanjuti.
Dalam banyak pabrik, data tersebar di berbagai platform:
Tantangan utamanya bukan hanya konektivitas, tetapi juga penyatuan konteks antar sistem yang punya struktur data berbeda.
Secara praktis, pipeline predictive maintenance biasanya mencakup:
Pilihan antara real-time, near real-time, atau batch harus disesuaikan dengan use case. Untuk aset yang bisa rusak dalam hitungan menit, real-time atau near real-time lebih relevan. Untuk failure yang berkembang lambat, batch harian bisa cukup.
Banyak proyek gagal bukan karena model jelek, tetapi karena data tidak siap dioperasionalkan.
Implementasi predictive maintenance yang berhasil hampir selalu dimulai dari use case yang sempit namun bernilai tinggi. Berikut pendekatan yang paling realistis dari perspektif konsultasi industri.
Langkah pertama adalah memilih area yang paling layak secara bisnis dan data.
Fokuslah pada aset yang memenuhi dua kriteria:
Contoh ideal adalah compressor utama, packaging line kritis, motor pada conveyor utama, chiller, pompa proses, atau spindle pada mesin bernilai tinggi.
Sebelum proyek dimulai, tetapkan tujuan yang spesifik seperti:
Baseline KPI wajib dibekukan di awal agar hasil pilot dapat dinilai objektif.
Setelah use case dipilih, tim perlu menentukan target prediksi yang benar. Jangan langsung mengasumsikan semua kasus harus memakai failure prediction yang kompleks.
Target umum yang bisa dipilih:
Kemudian lakukan feature engineering dari berbagai sumber data, misalnya:
Validasi model harus dilakukan bukan hanya secara historis, tetapi juga terhadap skenario operasional nyata. Ini penting agar model tidak terlihat bagus di notebook namun buruk di pabrik.
Inilah fase yang paling sering diabaikan. Prediksi tidak akan menghasilkan nilai jika tidak terhubung ke proses kerja.
Output model sebaiknya diintegrasikan ke:
Tim juga harus menentukan ambang tindakan yang jelas. Jika threshold terlalu sensitif, teknisi akan dibanjiri alarm. Jika terlalu longgar, kegagalan bisa lolos. Pendekatan terbaik adalah menyepakati kategori tindakan, misalnya:
Pelatihan pengguna akhir sangat penting. Teknisi dan engineer harus memahami arti alert, tingkat prioritas, dan cara memberi umpan balik ketika rekomendasi tidak sesuai kondisi lapangan.
Setelah pilot berjalan, ukur hasil terhadap KPI operasional dan finansial yang telah disepakati. Jangan memperluas proyek hanya karena model terlihat canggih; perluasan harus berdasarkan hasil bisnis yang nyata.
Lakukan evaluasi pada aspek berikut:
Model juga perlu disempurnakan secara berkala karena pola operasi mesin bisa berubah akibat pergantian produk, kondisi lingkungan, perubahan kecepatan produksi, atau maintenance yang mengubah karakteristik aset.
Jika pilot terbukti berhasil, perluasan dapat dilakukan ke:
Bahkan program yang didukung manajemen puncak tetap menghadapi hambatan teknis dan organisasi. Kuncinya bukan menghindari semua hambatan, tetapi mengantisipasinya dari awal.
Masalah teknis paling umum dalam machine learning in manufacturing meliputi:
Jika data failure sangat sedikit, anomaly detection sering menjadi titik awal yang lebih realistis dibanding supervised model penuh. Jika sensor belum lengkap, perusahaan bisa memulai dengan retrofit sensor pada aset paling kritis dulu, bukan seluruh pabrik sekaligus.
Tantangan organisasi sering lebih berat daripada tantangan model.
Contohnya:
Tanpa tata kelola lintas fungsi, predictive maintenance mudah berubah menjadi proyek data yang tidak pernah diadopsi operasi.
Berikut pendekatan praktis yang paling efektif:
Pilih satu aset atau failure mode yang dampaknya besar dan datanya paling siap. Ini memberi peluang menang lebih cepat.
Pastikan manajemen, maintenance, dan operasi menyetujui definisi keberhasilan yang sama. Hindari perdebatan setelah pilot selesai.
Setiap alert harus bisa diberi status oleh teknisi: benar, salah, perlu investigasi, atau tidak relevan. Ini meningkatkan kualitas model dari waktu ke waktu.
Model dengan recall tinggi tetapi false alarm berlebihan bisa merusak kepercayaan pengguna. Cari titik optimal yang bisa diterima lapangan.
Tentukan siapa menerima alert, siapa memvalidasi, kapan work order dibuat, dan bagaimana hasil tindakan dicatat.
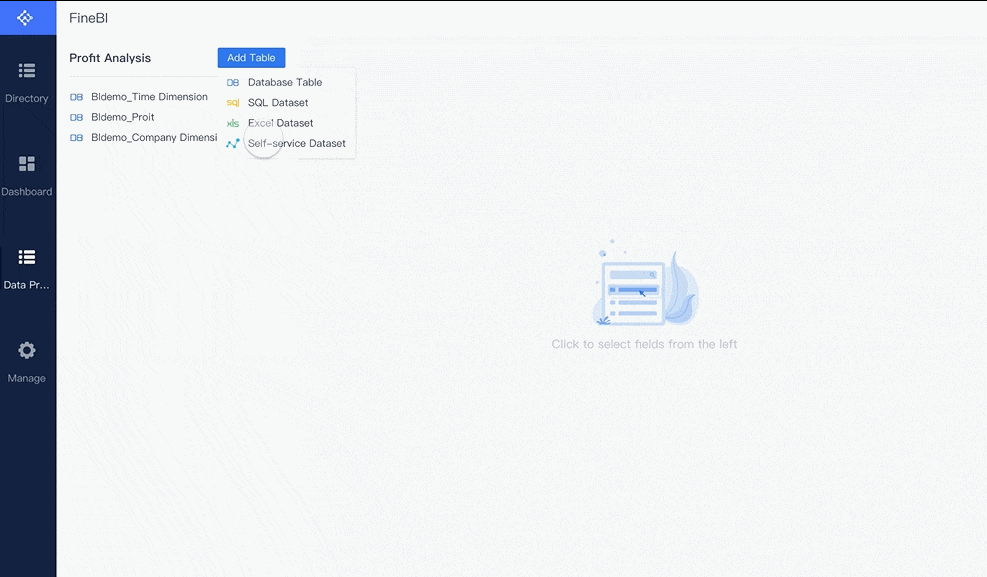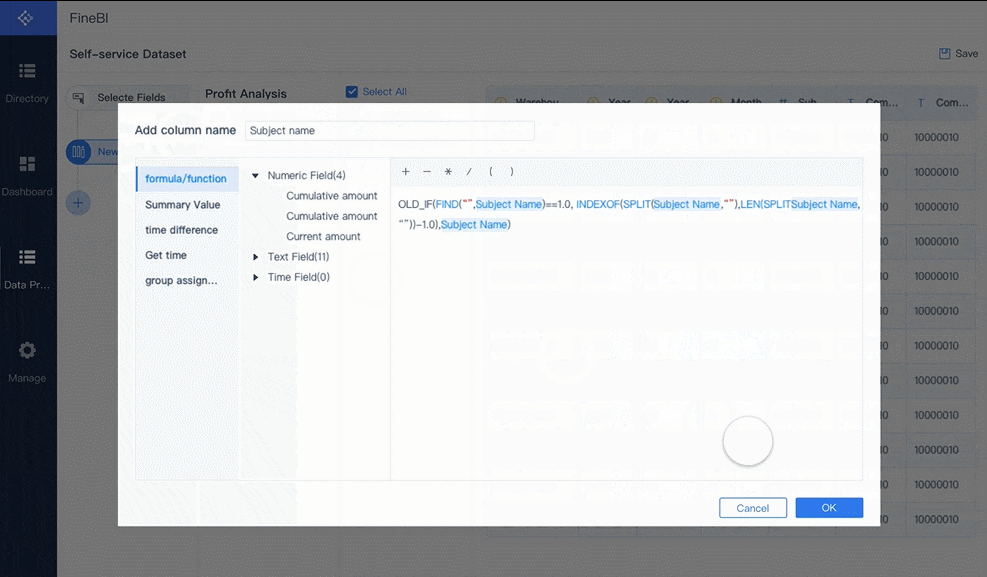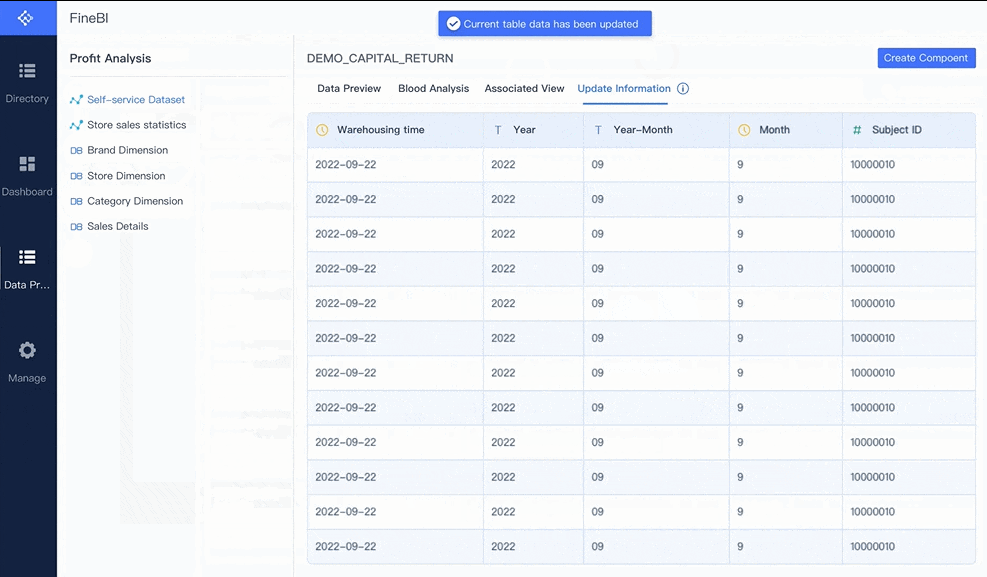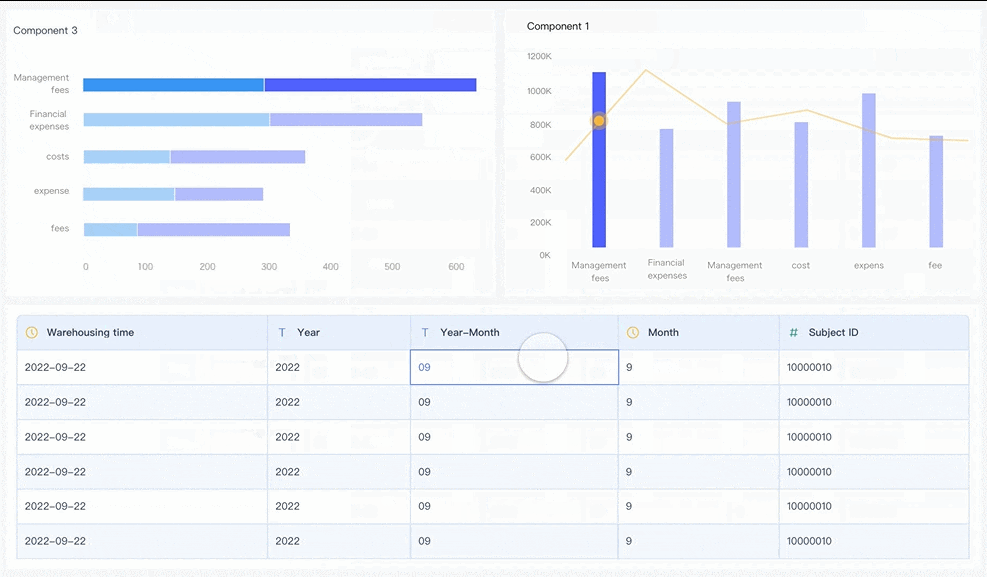
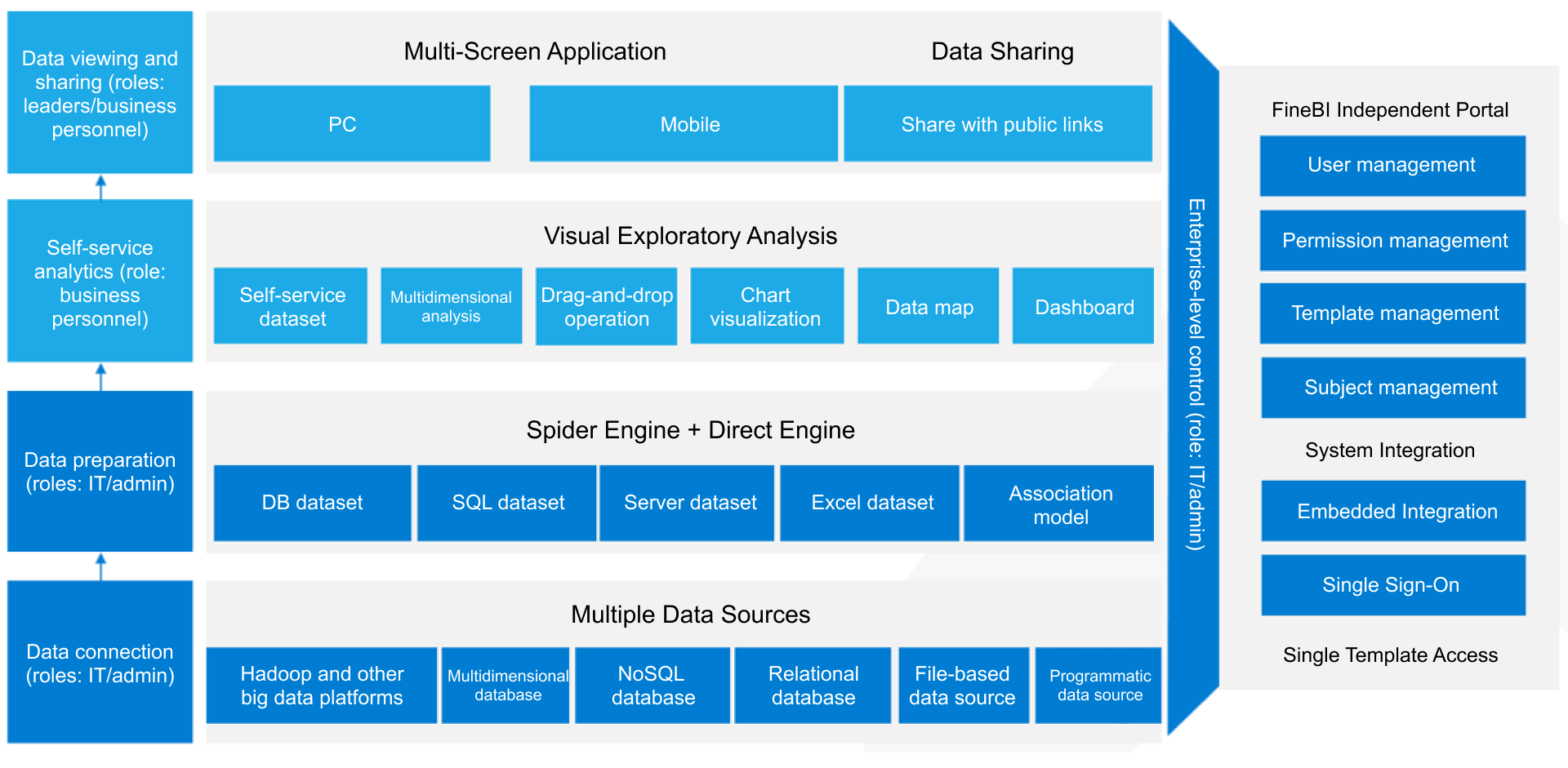
Secara konsep, predictive maintenance terlihat sederhana: kumpulkan data, latih model, tampilkan alert. Dalam praktik manufaktur, membangun semuanya secara manual jauh lebih kompleks. Tim harus mengintegrasikan data dari PLC, SCADA, MES, CMMS, dan ERP; menjaga kualitas data; menyelaraskan KPI; lalu menyajikan insight yang bisa langsung ditindaklanjuti oleh maintenance dan operasi.
Di sinilah FineBI menjadi enabler yang kuat.
Dengan FineBI, perusahaan dapat memanfaatkan template dashboard siap pakai, integrasi data yang lebih cepat, dan otomasi alur analitik untuk mengubah inisiatif machine learning in manufacturing menjadi proses bisnis yang operasional. Alih-alih membangun visualisasi, monitoring KPI, dan distribusi insight dari nol, tim dapat mempercepat implementasi melalui:
FineBI sangat relevan ketika organisasi ingin melangkah dari pilot yang terisolasi menuju tata kelola analitik yang lebih scalable. Pendekatan terbaik adalah menjadikan model machine learning sebagai mesin prediksi, lalu menggunakan FineBI sebagai lapisan pengambilan keputusan: tempat KPI dipantau, alert divisualisasikan, dan tindakan lintas fungsi dikelola dengan lebih konsisten.
Jika tujuan Anda adalah menekan downtime, meningkatkan reliabilitas aset, dan membangun proses predictive maintenance yang benar-benar dipakai di lapangan, jangan berhenti di eksperimen model. Bangun workflow lengkapnya — dan daripada merakit semuanya secara manual, gunakan FineBI untuk memanfaatkan template siap pakai dan mengotomatisasi keseluruhan alur kerja ini.
Predictive maintenance adalah pendekatan perawatan yang memprediksi potensi kerusakan mesin berdasarkan data kondisi aktual, bukan hanya jadwal servis. Machine learning membantu mengenali pola awal kegagalan dari sensor, histori perawatan, dan data operasi.
Reactive maintenance dilakukan setelah mesin rusak, sedangkan preventive maintenance mengikuti interval waktu atau jam operasi. Predictive maintenance menentukan waktu intervensi berdasarkan indikasi risiko kegagalan yang terdeteksi dari data.
Data yang umum dibutuhkan meliputi data sensor seperti temperatur, vibrasi, dan arus, ditambah histori work order, catatan kerusakan, dan konteks operasi mesin. Semakin lengkap dan konsisten datanya, semakin baik kualitas prediksi yang dihasilkan.
Mulailah dari aset atau lini produksi yang paling kritis dan memiliki dampak downtime terbesar. Tetapkan baseline KPI, siapkan arsitektur data yang rapi, lalu jalankan pilot sebelum diperluas ke skala produksi.

Penulis
Saber Chen
AI Product Architect, CPO
Artikel Terkait
IoT Adalah dan Cara Kerjanya dalam Predictive Maintenance Manufaktur: Implementasi + Dashboard
Sebagai seorang IT Manager atau Operations Director di sektor manufaktur, Anda pasti sering bergulat dengan $1 mesin yang tak terduga, biaya pemeliharaan yang melonjak, dan tekanan untuk meningkatkan Overall Equipment Ef
Yida Yin
2026 Juni 11

8 Contoh Aplikasi SCM untuk Manufaktur, Distribusi, Retail, dan Logistik: Mana yang Paling Cocok?
$1 adalah platform reporting dan $1 enterprise yang membantu bisnis memantau $1 $1 secara real time agar keputusan operasional lebih cepat dan akurat. Ringkasan 8 contoh aplikasi SCM dan cara memilih yang paling cocok Be
Yida Yin
2026 Mei 18

Apa Itu MES? Panduan Praktis Direktur Operasi untuk Memahami Peran MES di Lantai Produksi
Jika Anda memimpin operasi manufaktur dan masih mengandalkan spreadsheet, $1 akhir shift, atau data mesin yang tersebar di banyak sistem, maka pertanyaan apa itu MES bukan lagi sekadar istilah teknis. Ini adalah pertanya
Yida Yin
2026 Mei 13



