현대의 데이터 환경은 방대하고 복잡하지만, 이를 효과적으로 다루는 방법이 있다면 데이터 분석과 관리가 훨씬 더 효율적으로 이루어질 수 있습니다. 파이썬은 다양한 데이터 소스를 손쉽게 통합하고, 복잡한 데이터셋을 처리하는 데 강력한 도구로 자리잡았습니다. 이번 글에서는 파이썬을 활용해 데이터를 다운로드하고 통합하는 방법을 설명하며, 특히 복잡한 데이터도 쉽고 빠르게 연결하는 방법을 소개합니다. 데이터 통합을 통해 얻을 수 있는 효율성을 높이고, 분석 업무의 생산성을 극대화하는 팁을 제공할 예정이니, 파이썬을 활용한 데이터 통합에 대해 더 알아보세요.

Windows에서 파이썬 다운로드와 설치는 매우 쉽습니다. 아래 단계에 따라 진행하면 누구나 빠르게 파이썬을 사용할 수 있습니다.
💡 팁:
'Add Python to PATH' 옵션을 선택하면 명령 프롬프트 어디서나 python 명령어를 사용할 수 있습니다. 이 설정은 개발 환경을 훨씬 더 편리하게 만들어 줍니다.
파이썬 다운로드 과정에서 최신 버전을 선택하면 보안과 호환성 면에서 유리합니다. 설치 후에는 명령 프롬프트에서 python --version을 입력해 정상적으로 설치되었는지 확인하세요.
macOS에서도 파이썬 다운로드는 간단합니다. 아래 절차를 따라 진행하세요.
python-3.13.0-macos1.pkg 파일입니다.python3 -V 명령어로 설치된 파이썬 버전을 확인합니다.⚠️ 참고:
macOS에는 기본적으로 파이썬 2.7이 설치되어 있을 수 있습니다. 최신 파이썬 3 버전을 사용하려면 항상python3명령어를 입력하세요.
설치 중 오류가 발생할 수 있습니다. 예를 들어, 터미널에서 'zsh: command not found: python' 오류가 나오면, which python3로 경로를 확인하고, ~/.zshrc 파일에 alias python=python3를 추가하면 해결할 수 있습니다. 설정 변경 후에는 source ~/.zshrc 명령어로 적용하세요.
Linux에서는 대부분 파이썬이 기본 설치되어 있습니다. 설치 여부를 먼저 확인하고, 필요하다면 아래 방법으로 파이썬 다운로드와 설치를 진행하세요.
python3 --version 명령어로 설치 여부를 확인합니다.설치되어 있지 않다면, Ubuntu 기준으로 다음 명령어를 입력해 설치합니다.
sudo apt update
sudo apt install python3
sudo apt install python3-pip 명령어로 설치할 수 있습니다.python3 -V와 pip3 --version으로 정상 설치 여부를 확인하세요.📝 참고:
환경 변수가 자동으로 등록되지 않았다면,~/.bashrc또는~/.zshrc파일에 아래 내용을 추가할 수 있습니다.export PATH="/usr/local/bin/python3:$PATH"변경 후에는
source ~/.bashrc또는source ~/.zshrc로 적용하세요.
Linux에서는 소스 파일을 직접 다운로드해 설치할 수도 있습니다. 이 경우 공식 홈페이지에서 원하는 버전의 소스를 받아 압축을 풀고, ./configure, make, sudo make install 순서로 설치합니다. 여러 버전의 파이썬을 관리하려면 update-alternatives 명령어를 활용할 수 있습니다.
파이썬 다운로드와 설치는 운영체제마다 약간의 차이가 있지만, 공식 홈페이지와 명령어를 활용하면 누구나 쉽게 최신 버전을 사용할 수 있습니다.
파이썬 다운로드 후, 환경 변수(PATH)를 올바르게 설정해야 명령 프롬프트에서 언제든지 파이썬을 실행할 수 있습니다. 아래 순서대로 따라 하면 환경 변수 설정을 쉽게 마칠 수 있습니다.
C:\Users\사용자명\AppData\Local\Programs\Python\Python310\C:\Users\사용자명\AppData\Local\Programs\Python\Python310\Scripts\python을 입력해 정상 실행되는지 확인합니다.💡 팁: 환경 변수 설정이 바로 적용되지 않으면 컴퓨터를 재부팅하세요.
pip는 파이썬 패키지 설치와 관리를 도와주는 필수 도구입니다. 설치 후 pip가 정상적으로 동작하는지 확인하려면 아래 단계를 따라 하세요.
pip --version 또는 pip3 --version을 입력합니다.다운로드한 폴더에서 아래 명령어를 실행합니다.
python get-pip.py
pip --version 명령어로 정상 설치 여부를 확인합니다.📝 참고: pip가 없으면 패키지 설치가 불가능하니 반드시 설치 상태를 확인하세요.
여러 프로젝트를 진행할 때는 가상 환경을 활용하면 큰 도움이 됩니다. 가상 환경은 프로젝트마다 독립적인 파이썬 환경을 만들어 패키지 충돌을 방지합니다. 대표적인 명령어는 venv입니다. 아래 예시처럼 가상 환경을 만들 수 있습니다.
python -m venv myenv
가상 환경을 사용하면 각 프로젝트가 독립적으로 패키지 버전을 관리할 수 있습니다. 이렇게 하면 한 프로젝트의 패키지 변경이 다른 프로젝트에 영향을 주지 않습니다.
🚀 가상 환경을 활용하면 패키지 충돌 걱정 없이 다양한 프로젝트를 동시에 진행할 수 있습니다.
데이터 통합은 여러 곳에 흩어져 있는 데이터를 하나로 모으는 과정입니다. 다양한 시스템이나 부서에서 데이터를 관리한다면, 각각의 데이터가 따로 존재해 분석이나 활용이 어렵다는 점을 느낄 수 있습니다. 이때 데이터 통합을 활용하면 서로 다른 데이터 소스를 연결해 하나의 통합된 뷰를 만들 수 있습니다. 이렇게 하면 조직 내 여러 팀이 같은 데이터를 바탕으로 빠르고 정확하게 의사결정을 내릴 수 있습니다.
데이터 통합은 단순히 데이터를 모으는 것에 그치지 않습니다. 다양한 형식과 구조의 데이터를 결합해 표준화된 시스템을 구축할 수 있습니다. 이 과정에서 데이터의 품질이 높아지고, 비즈니스 인사이트를 얻는 데 큰 도움이 됩니다. 예를 들어, 여러 부서의 고객 정보를 통합하면 고객에 대한 360도 시각을 확보할 수 있습니다. 또한, 데이터 웨어하우스나 데이터 레이크를 구축해 정형, 비정형 데이터를 모두 분석에 활용할 수 있습니다.
데이터 통합을 통해 해결할 수 있는 주요 문제점과 효과를 표로 정리하면 다음과 같습니다.
💡 데이터 통합을 잘 활용하면 비용을 줄이고, 생산성을 높이며, 부서 간 협업도 훨씬 쉬워집니다. 데이터 기반 문화가 조직에 자리 잡으면서 경쟁력도 자연스럽게 높아집니다.
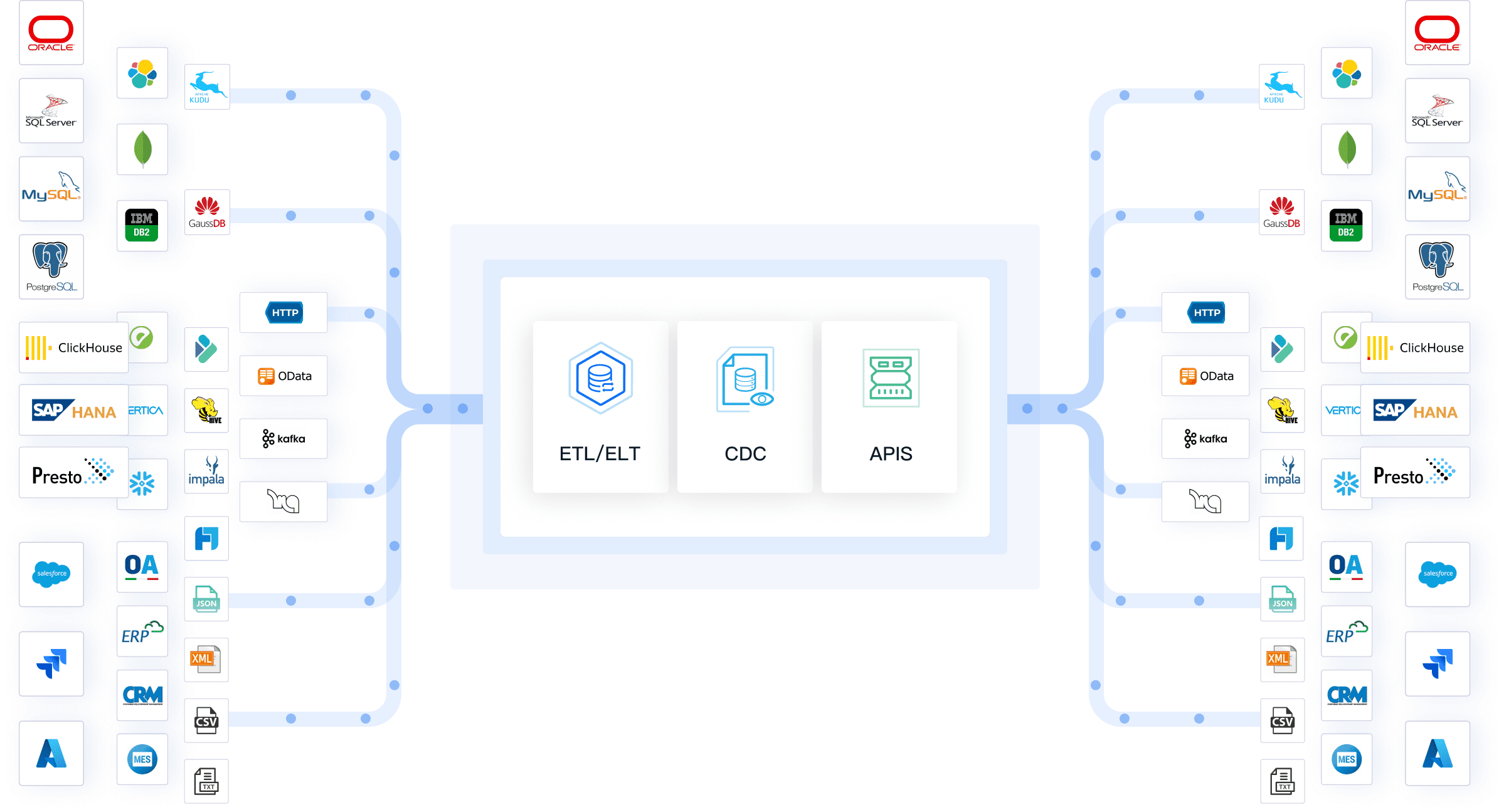
FineDataLink는 복잡한 데이터 통합을 쉽고 빠르게 해결할 수 있는 데이터 통합 플랫폼입니다. 이 플랫폼은 실시간 데이터 동기화, ETL/ELT, API 통합 기능이라는 세 가지 핵심 기능을 제공합니다. 여러 데이터 소스를 한 곳에 모으고, 데이터 품질을 높이며, 자동화된 데이터 파이프라인을 구축할 수 있습니다.
FineDataLink는 로우 코드 환경을 제공하므로, 복잡한 코딩 없이도 데이터 통합 작업을 진행할 수 있습니다. 파이썬 환경에서 FineDataLink를 활용하면, 데이터 분석, 머신러닝, 비즈니스 인텔리전스 등 다양한 프로젝트에서 데이터 연결과 처리가 훨씬 쉬워집니다.
💡 Tip:
FineDataLink는 100개 이상의 데이터 소스를 지원합니다. 데이터베이스, 파일, 클라우드, SaaS 등 다양한 환경에서 데이터를 자유롭게 통합할 수 있습니다.
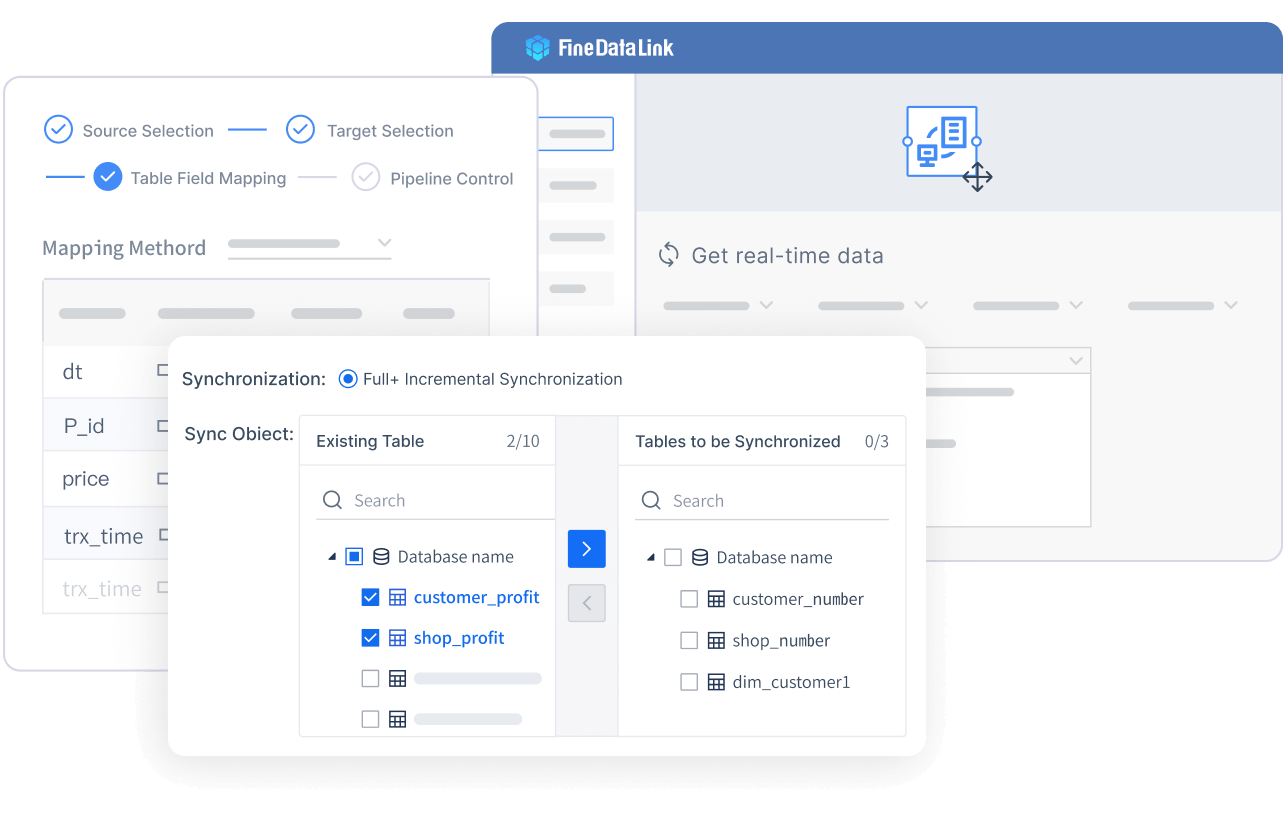
실시간 데이터 동기화는 데이터가 생성되거나 변경될 때마다 즉시 여러 시스템에 반영하는 기능입니다. FineDataLink는 밀리초 단위의 빠른 동기화로, 데이터 일관성과 신뢰성을 보장합니다.
이러한 실시간 동기화는 고객 경험을 개선하고, 비즈니스 신뢰성을 높이는 데 중요한 역할을 합니다.
FineDataLink는 스트리밍 데이터, 비정형 데이터(이메일, 이미지, 음성 등)도 실시간으로 처리할 수 있습니다. 이 기능은 데이터 품질을 높이고, 부서 간 협업과 신속한 의사결정을 지원합니다.
🚀 실무 팁:
실시간 동기화가 필요한 경우, FineDataLink의 시각적 인터페이스에서 데이터 흐름을 직접 설계해보세요. 파이썬으로 데이터 분석 코드를 작성할 때, 실시간으로 동기화된 데이터를 바로 활용할 수 있습니다.
FineDataLink는 ETL(Extract, Transform, Load)과 ELT(Extract, Load, Transform) 방식을 모두 지원합니다. 이 두 방식은 데이터 통합의 핵심입니다.
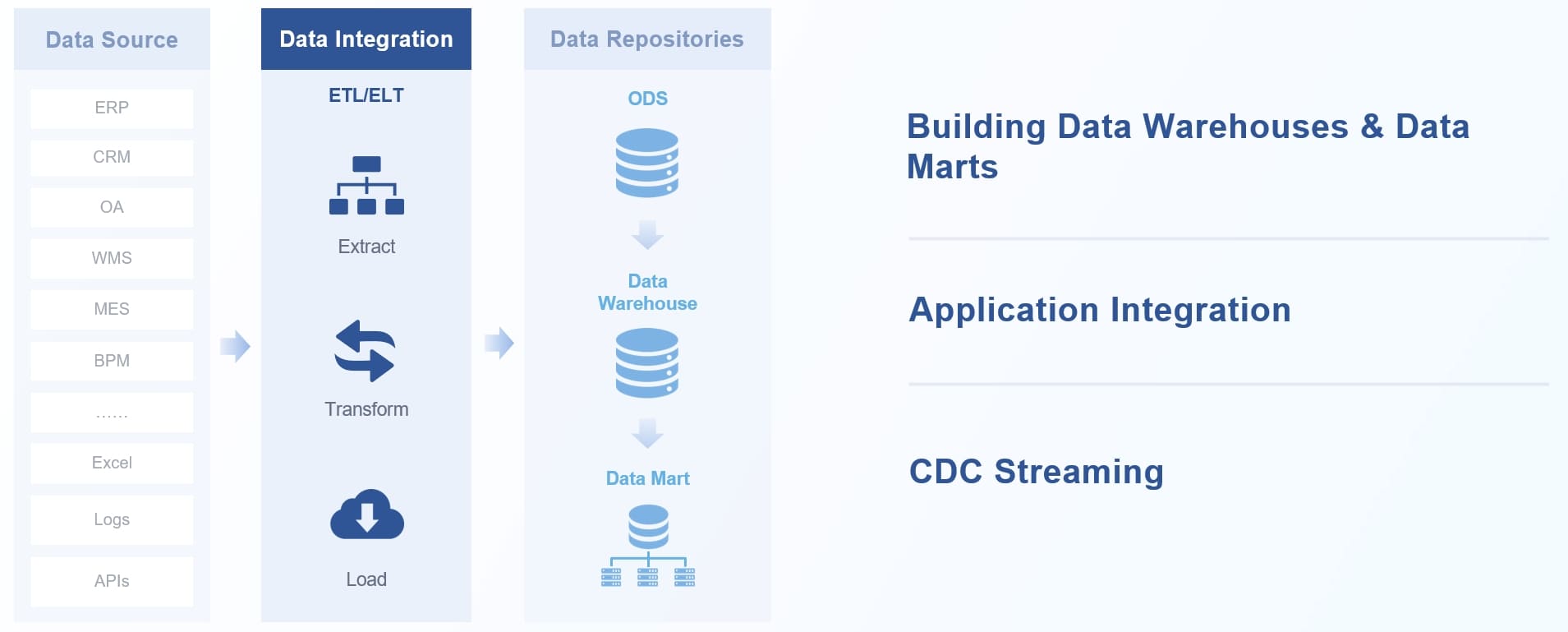
| 구분 | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| 처리 순서 | 추출 → 외부 변환 → 적재 | 추출 → 적재 → 내부 변환 |
| 변환 위치 | 외부(스테이징 영역) | 데이터 웨어하우스 내부 |
| 장점 | 데이터 품질과 일관성에 적합 | 대용량, 실시간 처리에 유리 |
| 활용 시나리오 | 데이터 품질이 중요한 경우 | 성능과 확장성이 중요한 경우 |
FineDataLink는 각 방식의 장점을 살려, 조직의 데이터 환경에 맞는 유연한 통합을 지원합니다. ETL은 데이터 품질과 일관성이 중요할 때, ELT는 대용량 데이터와 실시간 처리가 필요할 때 적합합니다.
💡 실무 적용 팁:
FineDataLink의 로우 코드 환경에서 ETL/ELT 파이프라인을 직접 설계해보세요. 파이썬 스크립트와 연동하면, 데이터 전처리와 분석 자동화가 한층 쉬워집니다.
API 통합은 서로 다른 시스템과 애플리케이션을 연결해 데이터를 주고받는 과정입니다. FineDataLink는 복잡한 API 연동도 손쉽게 처리할 수 있습니다.
| 주요 문제점 | FineDataLink의 해결 방안 |
|---|---|
| 다양한 데이터 소스와 형식 | 데이터 정제 및 변환으로 일관성 확보, 품질 향상 |
| 스트리밍 데이터 처리 | 실시간 데이터 통합, 낮은 지연 시간, 내구성 강화 |
| 비정형 데이터 처리 | 고급 텍스트 분석 및 자연어 처리 지원 |
| 기술 변화와 보안 | 자동화된 통합, 보안 및 규정 준수 지원 |
| 확장성과 효율성 | 대용량 데이터 처리, 비용 최적화, 운영 자동화 |
FineDataLink는 코드 작성 없이도 5분 만에 API 인터페이스를 개발할 수 있습니다.
ERP, MES, SaaS 등 다양한 시스템과의 연동이 매우 쉽습니다. 파이썬 환경에서 REST API를 호출하거나, 외부 데이터와 연동할 때 FineDataLink를 활용하면 개발 시간을 크게 줄일 수 있습니다.
📝 활용 예시:
파이썬으로 외부 시스템의 데이터를 실시간으로 받아와 분석하고 싶다면, FineDataLink에서 API 연동을 설정한 뒤 파이썬 코드에서 바로 데이터를 불러올 수 있습니다. 데이터 자동화, 실시간 알림, 대시보드 구축 등 다양한 업무에 활용할 수 있습니다.
타겟 고객 및 실무 적용 팁
FineDataLink는 데이터 엔지니어, 비즈니스 인텔리전스 담당자, 데이터 거버넌스 팀, 애플리케이션 개발자 등 데이터 통합이 필요한 모든 조직에 적합합니다. 여러 시스템의 데이터를 한 번에 통합하고, 실시간 분석과 자동화까지 구현하고 싶다면 FineDataLink를 적극 활용해보세요.
✅ 실전 체크리스트
- 실시간 데이터 동기화가 필요한 업무가 있는가?
- 여러 데이터 소스와 시스템을 통합해야 하는가?
- 데이터 품질과 보안이 중요한가?
- 파이썬 환경에서 데이터 분석, 자동화, 대시보드 구축이 필요한가?
FineDataLink를 활용하면 복잡한 데이터 통합도 쉽고 빠르게 해결할 수 있습니다. 파이썬과 함께 사용하면 데이터 기반 의사결정과 업무 자동화가 한층 더 쉬워집니다.
파이썬 다운로드와 데이터 통합 환경을 구축할 때, 아래 체크리스트를 따라가면 실수를 줄일 수 있습니다.
💡 아나콘다를 설치하면 데이터 분석에 필요한 여러 패키지와 툴을 한 번에 사용할 수 있습니다. 초보자라면 아나콘다 설치도 좋은 선택입니다.
이 체크리스트를 활용하면 파이썬 다운로드부터 환경 설정까지 한 번에 점검할 수 있습니다.
실제 데이터 통합 프로젝트에서는 예상치 못한 실수가 자주 발생합니다. 아래 팁을 참고하면 데이터 품질과 프로젝트 성공률을 높일 수 있습니다.
📝 데이터 통합 환경을 처음 구축한다면, 작은 프로젝트부터 시작해 경험을 쌓아가세요. 실수를 줄이고, 점차 복잡한 데이터 통합도 자신 있게 도전할 수 있습니다.
파이썬 다운로드부터 데이터 통합, 그리고 FineDataLink 활용까지 따라오면 데이터 분석 자동화와 다양한 데이터 소스 연결이 쉬워집니다. 데이터 통합을 자동화하면 비용과 시간을 줄이고, 직원들은 더 중요한 업무에 집중할 수 있습니다. 통합된 데이터는 분석 도구에서 바로 활용할 수 있어 빠른 의사결정이 가능합니다.


작성자
Seongbin
FanRuan에서 재직하는 고급 데이터 분석가
관련 기사
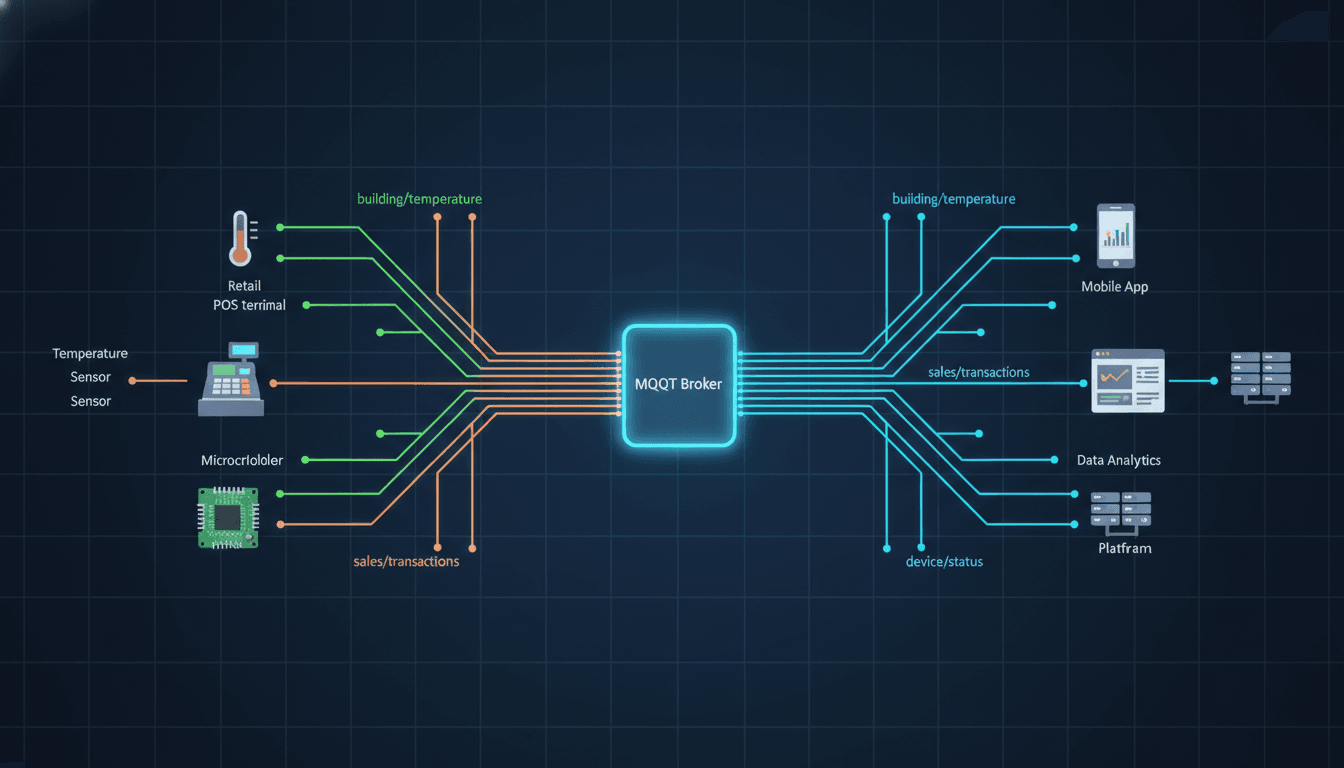
mqtt란 무엇인가요? 초보자를 위한 구조·동작 원리·핵심 용어 한 번에 이해하기
$1($1), 센서 수집, 원격 제어, POS 연동 같은 주제를 접하다 보면 빠지지 않고 등장하는 단어가 바로 mqtt 입니다. 처음 보면 이름부터 낯설고, 브로커·토픽·QoS 같은 용어도 한꺼번에 쏟아져서 어렵게 느껴질 수 있습니다. 하지만 큰 그림만 먼저 이해하면 mqtt는 오히려 단순한 편입니다. 핵심은 “누가 누구에게 직접 요청하는 방식”이 아니라, “중간 브로커를 통해 필요한 사람에
Seongbin
2026년 4월 27일

API 서버의 개념과 기본 역할
api 서버는 클라이언트와 서버 간 데이터 통신을 표준화하여 실시간 처리, 보안, 다양한 시스템 연동 등 핵심 역할을 수행합니다.
Seongbin
2025년 12월 29일
SQL을 활용한 데이터 추출 절차 쉽게 따라하기
SQL을 활용한 데이터 추출 절차와 실수 방지, 자동화 팁까지 실무에 바로 적용할 수 있는 핵심 방법을 안내합니다.
Seongbin
2025년 12월 22일



