실제 데이터 분석이나 AI 프로젝트를 시작할 때, 데이터에 오타나 누락이 있으면 결과가 크게 달라질 수 있습니다. 예를 들어, 설문조사에서 이름이 중복되거나 숫자가 잘못 입력된 경우를 떠올려 보세요. 이런 오류가 쌓이면 분석 시간이 늘어나고, 신뢰할 수 없는 결과가 나올 수 있습니다. 데이터 전처리 과정에서 이런 문제를 미리 해결하면, 분석의 정확도와 효율을 높일 수 있습니다.
FineDataLink는 여러 시스템과 데이터베이스에 흩어져 있는 데이터를 자동으로 연결·통합해 주는 데이터 파이프라인 플랫폼입니다. 반복적인 수작업 없이도 ERP, MES, 엑셀 등 다양한 소스의 데이터를 실시간으로 동기화할 수 있으며, 전처리 과정에서 발생하는 오류를 최소화해 분석 품질을 안정적으로 유지합니다. 이를 통해 분석 전에 데이터를 수동으로 정리하던 시간을 크게 줄이고, AI 프로젝트나 BI 분석 단계에 바로 활용할 수 있습니다.

데이터 전처리는 원시 데이터를 분석이나 AI 모델 학습에 적합한 형태로 바꾸는 모든 과정을 말합니다. 여러분이 실제로 데이터를 다룰 때, 데이터 전처리는 단순히 오류를 고치는 것에 그치지 않습니다. 결측값이나 중복값을 처리하고, 데이터의 크기나 단위를 맞추는 작업, 필요 없는 정보를 줄이는 과정까지 모두 포함합니다.
아래 표를 보면 데이터 전처리에서 어떤 작업들이 이루어지는지 쉽게 알 수 있습니다.
| 주요 작업명 | 설명 | 구체적 예시 및 방법 |
|---|---|---|
| 데이터 클렌징 | 오류나 불완전한 데이터를 수정하거나 제거하는 과정 | 결측값 처리, 중복 제거, 이상값 수정 |
| 데이터 통합 | 여러 출처의 데이터를 하나로 합치는 과정 | 데이터베이스, 스프레드시트, 텍스트 파일 통합 |
| 데이터 변환 | 데이터를 분석에 적합한 형태로 바꾸는 과정 | 정규화, 스케일링, 인코딩(레이블, 원-핫) |
| 데이터 축소 | 데이터 양을 줄이면서 중요한 정보는 유지하는 과정 | 피처 선택, 차원 축소, 샘플링 |
| 데이터 불균형 처리 | 클래스 불균형 문제를 해결하는 과정 | 오버샘플링, 언더샘플링, SMOTE 기법 |
이처럼 데이터 전처리는 데이터 품질을 높이고, 분석 결과의 신뢰성을 확보하는 데 꼭 필요합니다.
데이터를 다룰 때 자주 듣는 용어가 바로 데이터 정제입니다. 데이터 정제는 데이터 전처리의 한 부분입니다. 데이터 정제는 결측값이나 이상값, 중복 데이터를 찾아내고, 이를 제거하거나 수정하는 작업에 집중합니다. 예를 들어, 설문조사에서 빠진 응답을 평균값으로 채우거나, 잘못 입력된 값을 올바르게 고치는 일이 여기에 해당합니다.
반면 데이터 전처리는 데이터 정제보다 더 넓은 개념입니다. 데이터 정제뿐 아니라, 데이터 변환(예: 숫자 범위 맞추기, 범주형 데이터 인코딩), 데이터 통합, 데이터 축소, 데이터 증강 등 다양한 작업이 포함됩니다. 실제로 이미지 데이터를 다룰 때는 회전이나 뒤집기 같은 증강 기법을 적용해 데이터의 다양성을 높일 수 있습니다. 텍스트 데이터에서는 동의어로 문장을 바꿔서 데이터의 폭을 넓히기도 합니다.
데이터 전처리를 제대로 하면 머신러닝 모델의 성능이 크게 향상됩니다. 데이터 정제는 데이터의 정확성과 일관성을 높이고, 전처리는 전체 데이터의 품질과 분석 효율을 높입니다.

여러분이 데이터 분석을 시작할 때, 데이터 품질이 가장 중요합니다. 데이터 전처리를 통해 데이터의 정확성과 일관성을 높일 수 있습니다. 예를 들어, 결측값이나 이상치를 처리하면 데이터가 더 완전해집니다. 범주형 데이터를 숫자로 바꾸거나, 데이터의 크기를 맞추는 작업도 필요합니다. 이런 과정을 거치면 분석 결과가 더 신뢰할 수 있게 됩니다.
아래 표는 데이터 전처리가 데이터 품질을 어떻게 높이는지 보여줍니다.
| 전처리 단계 | 설명 및 효과 |
|---|---|
| 결측치 처리 | 결측치를 채우거나 삭제하여 데이터 완전성 확보 |
| 이상치 제거 | 이상치를 식별하고 제거 또는 대체하여 모델 성능 향상 |
| 데이터 스케일링 | 표준화, 정규화로 데이터 크기 조정, 모델 학습 안정화 |
| 범주형 데이터 인코딩 | 범주형 변수를 숫자형으로 변환하여 모델 입력 가능하게 함 |
| 특성 선택 및 추출 | 모델에 유용한 특성 선택 및 새로운 특성 생성으로 성능 향상 |
| 데이터 정규화 | 데이터 분포 조정으로 학습 안정화 및 성능 개선 |
| 데이터 변환 | 텍스트 토큰화, 이미지 전처리 등으로 모델 이해도 향상 |
2023년 한 연구에서는 하수처리장 센서 데이터를 분석할 때 데이터 전처리를 적용했습니다. 그 결과, 예측 모델의 정확도와 신뢰도가 크게 향상되었습니다. 이처럼 데이터 전처리는 분석 결과의 신뢰성을 높이는 데 중요한 역할을 합니다.
데이터 전처리를 소홀히 하면 여러 가지 문제가 생깁니다.
데이터 전처리를 제대로 하지 않으면, 분석 결과를 신뢰할 수 없습니다. 실제 업무에서 잘못된 데이터로 인해 잘못된 의사결정을 내릴 위험도 커집니다.
여러분이 데이터 분석이나 AI 프로젝트에서 좋은 결과를 얻고 싶다면, 데이터 전처리 과정을 반드시 거쳐야 합니다.
데이터 전처리의 첫 단계는 데이터를 수집하고 점검하는 일입니다. 데이터를 모을 때, 다양한 소스에서 정보를 가져오게 됩니다. 이 과정에서 데이터의 정확성과 신뢰성을 반드시 확인해야 합니다. 데이터 수집 단계에서 자주 발생하는 오류는 다음과 같습니다.
이런 오류를 줄이기 위해서는 데이터 유효성 검사, 오류 처리 메커니즘, 정기적인 데이터 모니터링이 필요합니다. FineDataLink와 같은 데이터 통합 플랫폼을 사용하면, 여러 데이터 소스를 한 번에 연결하고 실시간으로 데이터를 동기화할 수 있습니다. 이 플랫폼은 데이터 수집 계획 수립부터, 자동화된 데이터 추출, 오류 감지, 개인정보 보호 정책 적용까지 지원합니다. 여러분은 FineDataLink의 시각적 인터페이스를 통해 데이터 흐름을 쉽게 점검하고, 데이터 품질을 실시간으로 모니터링할 수 있습니다.
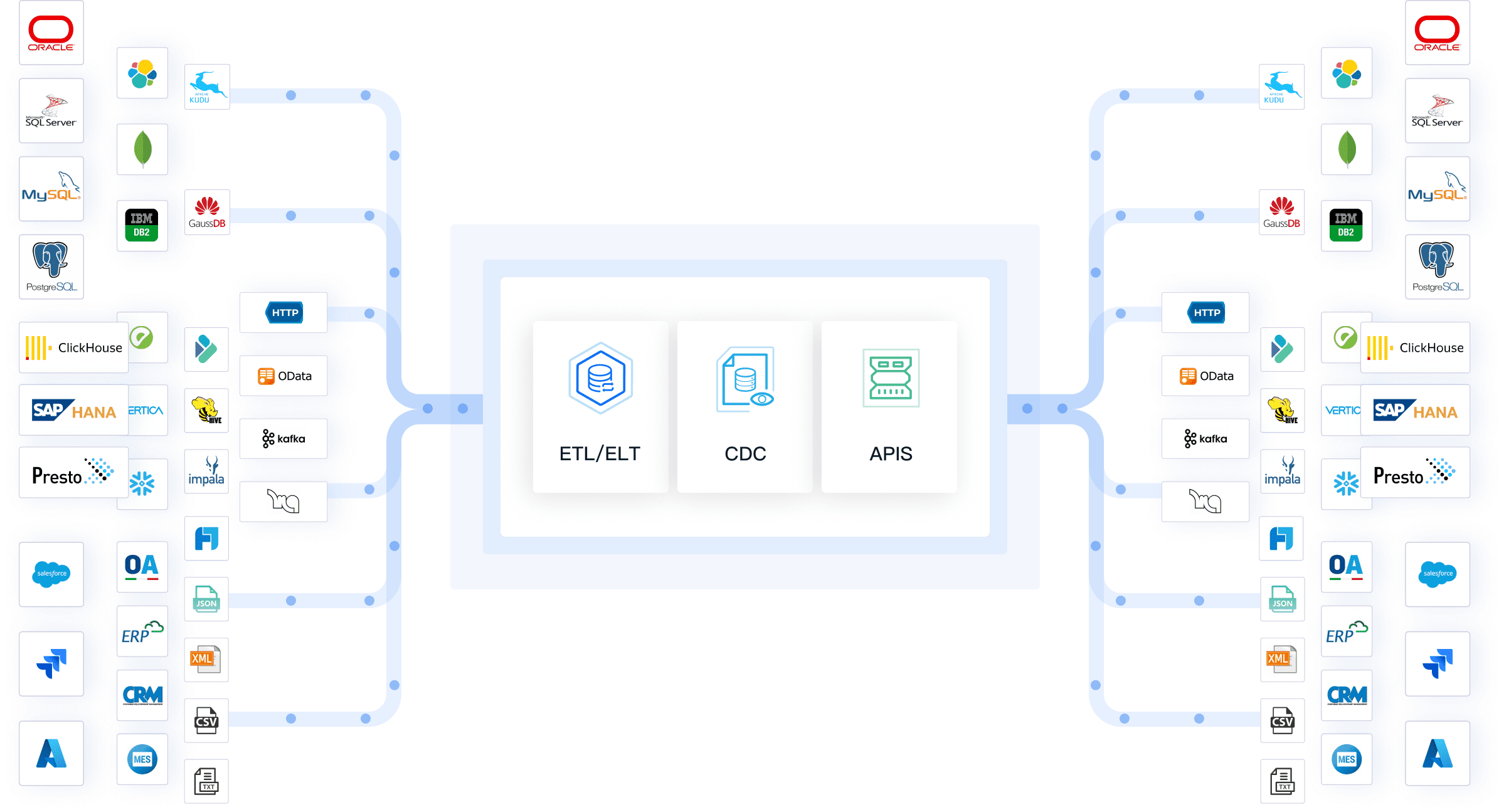
데이터 수집 단계에서 꼼꼼한 점검과 자동화 도구의 활용은 전체 데이터 전처리의 성공을 좌우합니다.
데이터를 수집한 후에는 결측치와 이상치를 처리해야 합니다. 결측치는 값이 비어 있거나 누락된 경우를 말합니다. 이상치는 정상 범위에서 벗어난 값입니다. 이 두 가지를 제대로 처리하지 않으면 분석 결과가 왜곡될 수 있습니다.
| 처리 기법 | 장점 | 단점 |
|---|---|---|
| 행/열 제거 (dropna) | 간단하고 빠름 | 데이터 손실 위험 존재 |
| 평균/중앙값/최빈값 대체 | 쉬운 적용, 통계적 안정성 제공 | 데이터 왜곡 가능성 있음 |
| 그룹별 평균 대체 | 데이터 맥락 반영 가능 | 그룹 세분화가 안 되면 효과 미비 |
| 모델 기반 예측 대체 | 정교한 예측 가능 | 과적합 위험, 복잡도 증가 |
| KNN, Iterative Imputer | 고차원 데이터에 효과적 | 속도 저하, 복잡성 있음 |
이상치는 IQR, Z-score, 머신러닝 기반 탐지 등 다양한 방법으로 찾을 수 있습니다. 처리 방법으로는 삭제, 클리핑, 변환, 별도 라벨링 등이 있습니다.
FineDataLink는 결측치와 이상치 탐지 및 처리를 자동화할 수 있습니다. 예를 들어, 데이터 파이프라인에서 결측값을 자동으로 채우거나, 이상치를 탐지해 별도 파일로 분리할 수 있습니다. FineDataLink의 ETL/ELT 기능을 활용해 대량의 데이터를 빠르게 처리하고, 데이터 품질을 높일 수 있습니다.
결측치와 이상치를 빠르고 정확하게 처리하면, 데이터 분석의 신뢰도가 크게 향상됩니다.
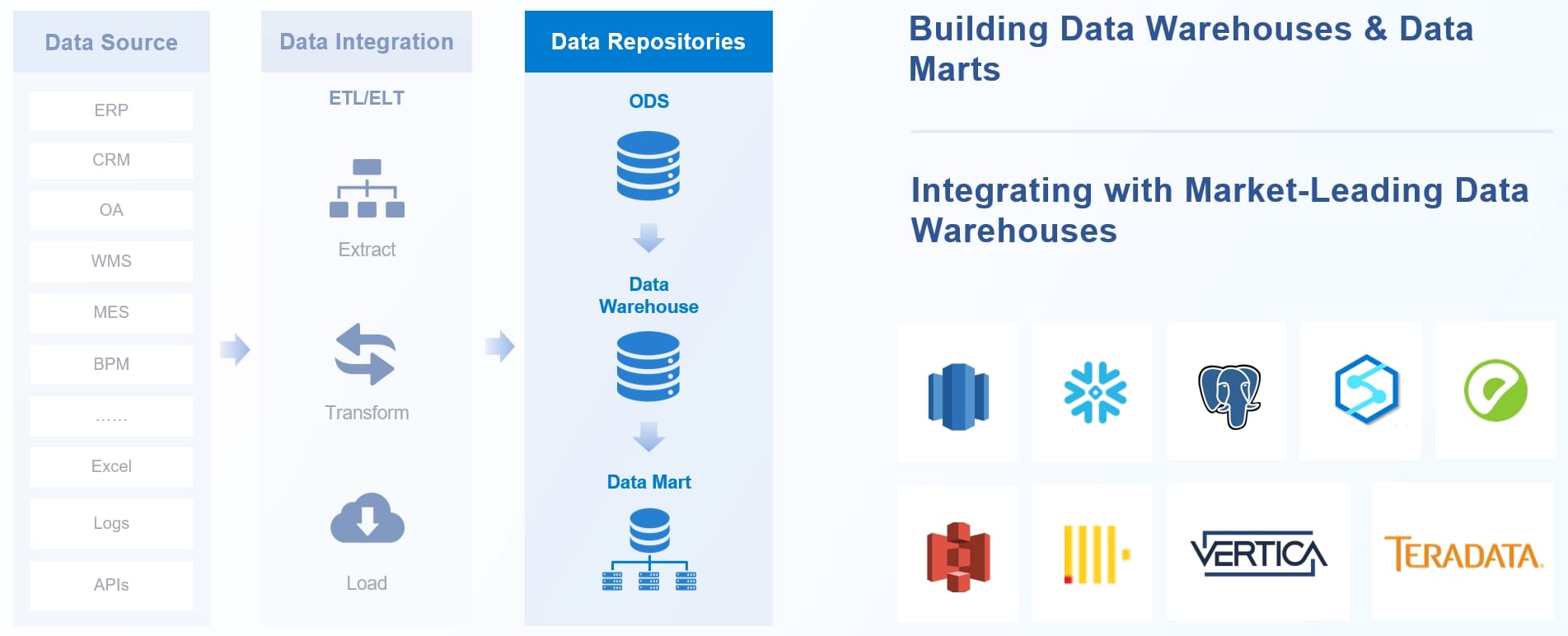
마지막 단계는 데이터를 분석에 적합한 형태로 변환하고, 여러 소스의 데이터를 통합하는 과정입니다. 여러분은 범주형 데이터를 숫자로 바꾸거나, 데이터의 단위를 맞추는 작업을 하게 됩니다. 여러 데이터베이스, 파일, 클라우드 등 다양한 소스에서 데이터를 가져와 하나로 합치는 것도 이 단계에 포함됩니다.
| 구분 | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| 변환 시점 | 데이터 적재 전에 변환 | 데이터 적재 후에 변환 |
| 적합한 환경 | 소규모 데이터, 전통적 데이터 웨어하우스 | 대규모 데이터, 클라우드 기반 데이터 레이크 |
| 장점 | 데이터 품질 보장, 구조화된 데이터 처리 | 빠른 데이터 적재, 유연성 |
FineDataLink는 100개 이상의 데이터 소스를 지원하며, 실시간 동기화와 ETL/ELT 자동화 기능을 제공합니다. 여러분은 로우 코드 환경에서 복잡한 데이터 변환 작업을 손쉽게 설정할 수 있습니다. API 통합 기능을 활용하면 SaaS, 클라우드, 온프레미스 등 다양한 시스템 간 데이터 이동도 간단하게 처리할 수 있습니다.
데이터 변환과 통합을 자동화하면, 분석 준비 시간을 크게 줄이고 데이터 품질을 높일 수 있습니다.
아래 표는 데이터 전처리의 주요 단계를 정리한 것입니다.
| 단계 | 설명 |
|---|---|
| 데이터 병합 | 여러 출처의 데이터를 하나로 통합, 열 이름 통일 등 사전 처리 필요 |
| 범주 변수 처리 | 문자형 범주 변수를 숫자형으로 변환 |
| 결측값 처리 | NA, Null 등 결측값 확인 및 적절한 처리 |
| 이상값 처리 | 정상 범주에서 벗어난 값 탐지 및 처리 |
FineDataLink와 같은 데이터 통합 플랫폼을 활용하면, 데이터 전처리의 모든 단계를 자동화하고 효율적으로 관리할 수 있습니다. 여러분은 데이터 품질을 높이고, 분석과 AI 모델링의 성공 가능성을 높일 수 있습니다.
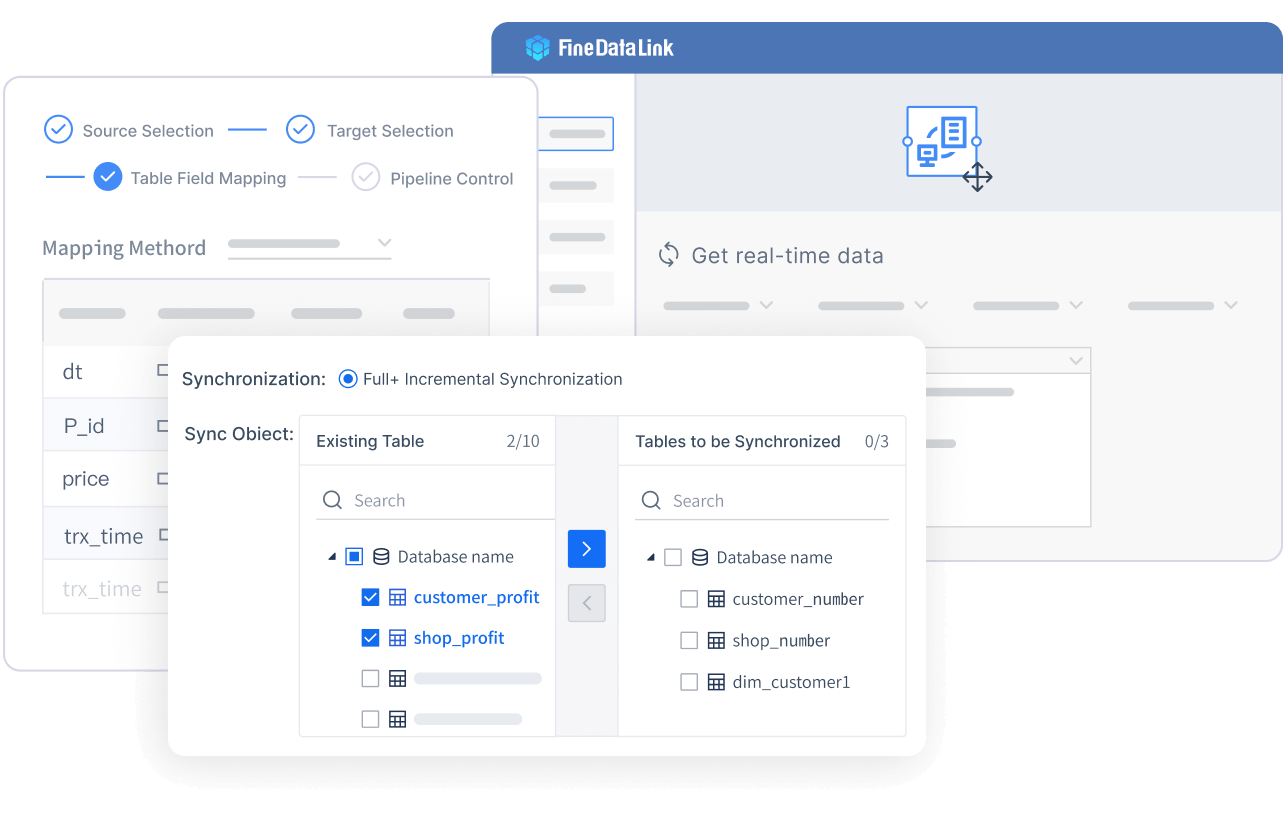
FineDataLink를 사용하면 여러 데이터 소스를 한 번에 연결할 수 있습니다. 실시간 데이터 통합 기능을 통해 데이터가 항상 최신 상태로 유지됩니다. 여러분은 대규모 데이터 세트를 반복적으로 새로 고칠 필요가 없습니다. 시스템은 필요한 부분만 빠르게 동기화합니다. 이렇게 하면 리소스 사용량이 안정적으로 유지되고, 데이터 처리 속도가 빨라집니다. 여러 부서가 동일한 데이터 뷰를 실시간으로 공유할 수 있습니다. 협업이 쉬워지고, 데이터 기반 의사결정이 빨라집니다.
FineDataLink의 시각적 인터페이스는 데이터 흐름을 한눈에 보여줍니다. 여러분은 복잡한 코딩 없이 데이터 전처리 과정을 쉽게 관리할 수 있습니다.
실시간 데이터 통합은 데이터 전처리의 효율을 극대화하고, 기업의 데이터 활용 가치를 높입니다.
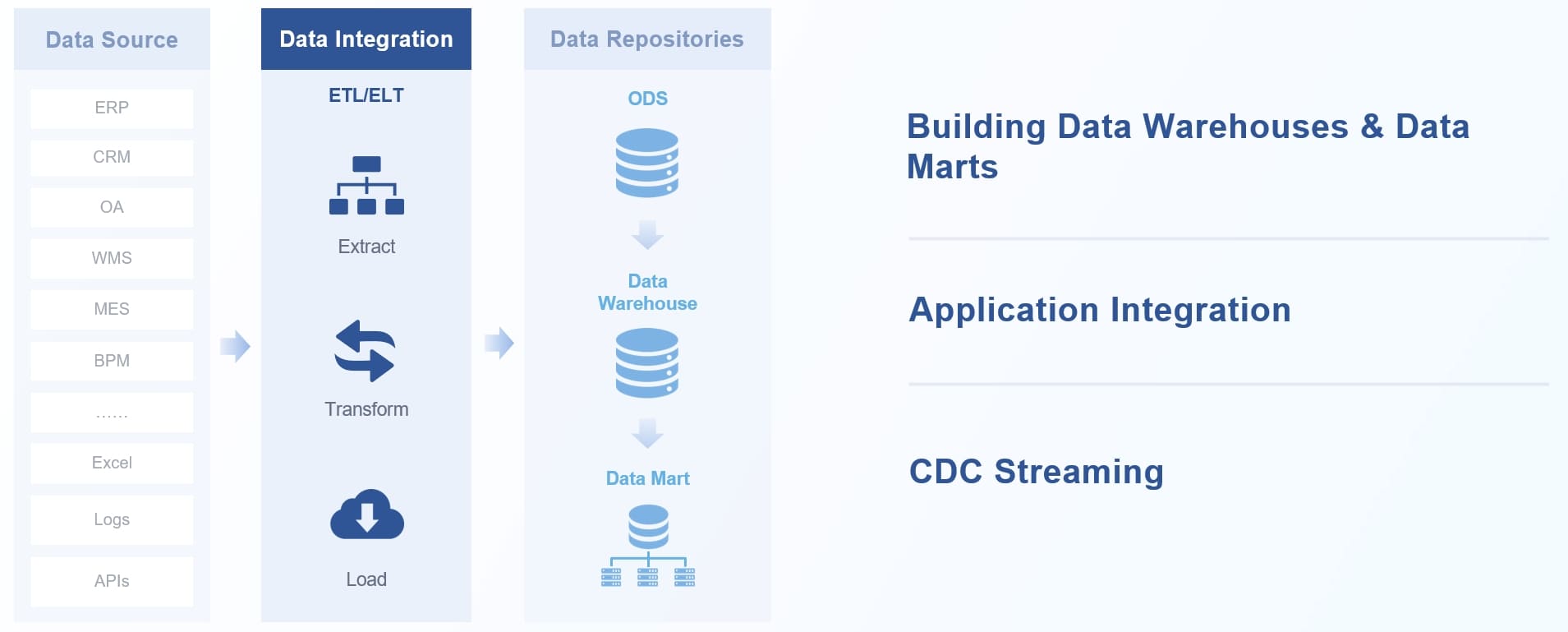
FineDataLink는 ETL(추출, 변환, 적재)과 ELT(추출, 적재, 변환) 과정을 자동화합니다. 로우 코드 환경에서 데이터 변환 규칙을 손쉽게 설정할 수 있습니다. 100개 이상의 데이터 소스를 지원하므로, 다양한 시스템에서 데이터를 가져와 통합할 수 있습니다.
ETL/ELT 자동화 덕분에 데이터 준비 시간이 크게 단축됩니다. 수작업 오류가 줄어들고, 데이터 품질이 일정하게 유지됩니다. API 통합 기능을 활용하면 SaaS, 클라우드, 온프레미스 환경에서도 데이터 이동이 간편해집니다.
실제 기업에서는 FineDataLink를 도입해 데이터 웨어하우스 구축 시간을 절반 이상 단축한 사례가 있습니다. 여러분도 데이터 전처리 자동화를 통해 분석과 AI 프로젝트의 성공 가능성을 높일 수 있습니다.
데이터 전처리가 잘 이루어지면 AI 모델의 정확도가 평균 10% 이상 높아지고, 학습 시간도 단축됩니다. 반대로 전처리가 부족하면 분석 결과가 왜곡될 수 있습니다. FineDataLink 같은 솔루션을 활용하면 데이터 품질을 쉽게 높일 수 있습니다. 실무에 적용하려면 아래와 같은 실습 자료를 참고해 보세요.
| 주요 내용 및 특징 | 설명 |
|---|---|
| 전처리 개념 및 역할 | 데이터 분석에서 전처리의 중요성과 기본 개념 설명 |
| 프로그래밍 언어 활용 | SQL, R, 파이썬을 이용한 전처리 구현 방법 소개 |
| 실무 적용 | 현장 경험 기반 예제와 실습 문제 제공 |
데이터 전처리는 단순히 분석을 위한 준비 과정이 아니라, 결과의 정확성과 신뢰성을 좌우하는 핵심 단계입니다. FineDataLink는 복잡한 데이터 전처리 과정을 자동화하고, 다양한 데이터 소스를 손쉽게 연결하여 일관된 품질의 데이터를 제공합니다. 지금 FineDataLink를 통해 번거로운 전처리 업무를 간소화하고, 더 빠르고 정확한 데이터 분석을 시작해 보세요.


작성자
Seongbin
FanRuan에서 재직하는 고급 데이터 분석가
관련 기사
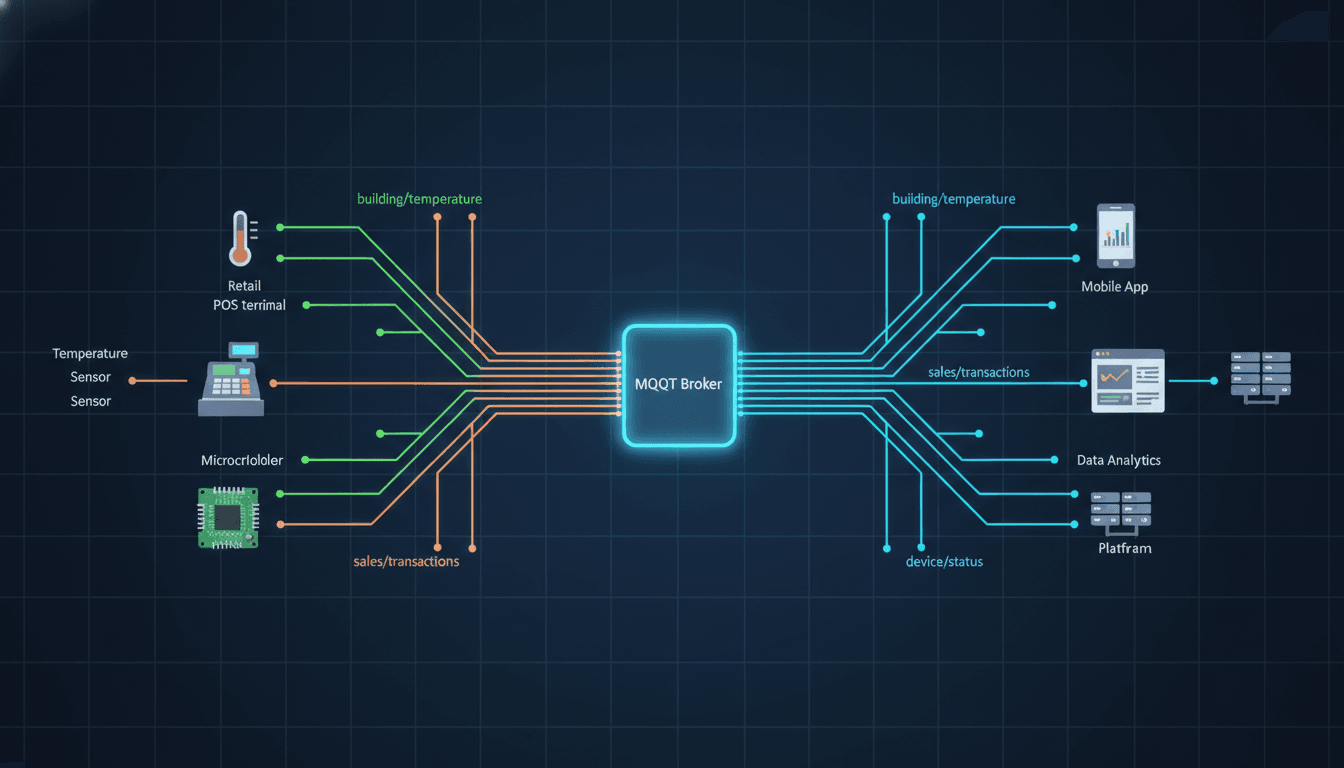
mqtt란 무엇인가요? 초보자를 위한 구조·동작 원리·핵심 용어 한 번에 이해하기
$1($1), 센서 수집, 원격 제어, POS 연동 같은 주제를 접하다 보면 빠지지 않고 등장하는 단어가 바로 mqtt 입니다. 처음 보면 이름부터 낯설고, 브로커·토픽·QoS 같은 용어도 한꺼번에 쏟아져서 어렵게 느껴질 수 있습니다. 하지만 큰 그림만 먼저 이해하면 mqtt는 오히려 단순한 편입니다. 핵심은 “누가 누구에게 직접 요청하는 방식”이 아니라, “중간 브로커를 통해 필요한 사람에
Seongbin
2026년 4월 27일

API 서버의 개념과 기본 역할
api 서버는 클라이언트와 서버 간 데이터 통신을 표준화하여 실시간 처리, 보안, 다양한 시스템 연동 등 핵심 역할을 수행합니다.
Seongbin
2025년 12월 29일
SQL을 활용한 데이터 추출 절차 쉽게 따라하기
SQL을 활용한 데이터 추출 절차와 실수 방지, 자동화 팁까지 실무에 바로 적용할 수 있는 핵심 방법을 안내합니다.
Seongbin
2025년 12월 22일



